How do machine learning algorithms work?
On the example of LIME and model explainability

Krzysztof Udycz
AI Engineer
May 21th, 2019
Machine learning and artificial intelligence have already entered many areas of life.
The voice assistants use them in our smartphones, they suggest products for online shopping or videos to watch to suit our personal preferences.
While they may usually seem well fitted, this is a two-way deal. Choosing the solutions suggested by algorithms, we agree to a kind of trust in these choices.
Note that models such as random forests or deep neural networks are classifiers (algorithms for determining the decision class of objects) that take thousands of factors into account. They are so vast that it is easy to lose control over the result of their learning and the reasons for the predictions generated.
The black box of AI, or how machine learning algorithms work
To easily visualize the operation of machine learning algorithms, imagine a black box. Algorithms perform actions for the input data to return a specified result. However, they are not able to really explain to the man how the decision was made. They present a configuration about which we do not have full knowledge, exactly as if it was locked in a black box.
Therefore, the attempt to understand on what basis these forecasts are made is one of the key elements in the development of artificial intelligence solutions.
Users need to be sure that the model will work well on real data, according to valuable metrics. If it is not trustworthy, it should not be used.
Interpretability of machine learning models and systems
Here we get the help of a technique that focuses on explaining complex models (explainable artificial intelligence), which is often recommended in situations where the decisions made by the AI directly affect a human being.
It aims to create classifiers that:
- Provide a valid explanation of where and how artificial intelligence systems make decisions.
- Maintain a high level of learning efficiency with the ability to explain the data generated. Currently, models with a high level of predictive accuracy are poorly interpretable.
- Both results and predictions are generated simultaneously.
Why is explainable artificial intelligence so important?
As I mentioned before, there are a number of reasons why the “explainability” of artificial intelligence is so important. These include, among other things:
- Trust building – Can we trust that our predictions are correct? Can models we don’t understand hurt people?
- Control – Do we know exactly how our AI system behaves?
- Feeling secure – Can every decision be subject to security regulations and warnings of violations based on the explanations?
- Prediction Assessment – Can we understand the behaviour of the model? Are explanations sufficient? Is our data behaving as expected?
- Improvement and enhancement of the model – How can we improve, evaluate and possibly enhance our classification based on the explanations?
- Better decision making – Is our model smart? Can we make better decisions thanks to the explanations?
From a technical point of view, the explainability of machine learning systems is crucial because it gives a sense of control and safety and allows us to determine whether our model behaves correctly.
In addition, it builds trust with customers who can review the reasoning behind their decisions to see if they can better comply with legislation (such as RODO / GDPR) in which they have the right to be clarified.

Only 1 mistake!

The results of the classifier recognizing whether there is a wolf or a husky dog in the photo. Source: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
Let’s look at the example above. It shows the result of the classifier recognizing whether there is a wolf or a husky dog in the photo. You can see that this is a system of high precision prediction – it was wrong only once. The model stated that there was a wolf in the lower left corner of the photo, although in reality it is a husky dog. The remaining images were classified correctly.
So the question is: “Which approach is better?”. Blindly believing in the correctness of the model and based only on the quality of the predictions, or trying to explain on what basis the decisions were made?

The results of the classifier recognizing whether the photo contains a wolf or a husky dog and the information on which part of the image the model made the decision. Source: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
On the illustration above we see which parts of the picture were informative for our classifier. It turns out that instead of wolves, it detects snow! If not for the approach to explainability of artificial intelligence models, we would not know that decisions were made on the basis of the wrong parts of the photo.
So the answer is: don’t trust the model blindly! Without knowing on what basis it makes its choices, we don’t know if it’s the right signal, noise or background. So the key is to try to understand how it works and to generate explanations.
LIME - Local Interpretable Model-Agnostic Explanations
The LIME framework comes in handy, whose main task is to generate prediction explanations for any classifier or machine learning regressor.
This tool is written in Python and R programming languages. Its main advantage is the ability to explain and interpret the results of models using text, tabular and image data.
Classifier and regressor - do you know these terms?
The classifier predicts from a defined set a class or category for a given observation, e.g., an e-mail message can be marked with one of two classes: “spam’ or ‘ham’ (a word that is not spam).
The regressor however, tries to estimate the real value – an integer or a floating point. This number is not previously defined in any set, for example, predicting the amount for which the house will be sold we can get the amount in the range of EURO 100.000 to EURO 160.000.
The explanation of the acronym “LIME” indicates the key attributes of this acronym:
- Local – uses locally weighted linear regression,
- Interpretable Explanations – allows you to understand what a model does, which features it chooses to create a classifier,
- Model-Agnostic – treats the model as a black box.
How does LIME work?
The explanation is generated by bringing the original model (black box) closer to the explained model (such as linear classifier with several non-zero parameters). The interpretable model is created on the basis of the perturbation of the original instance from which the selected components were excluded. This can be for example removing words or hiding a part of an image.
Imagine that you want to explain a classifier that predicts how likely it is that a tree frog is in the image. The first step is to divide the image into interpretable parts.

Transformation of the image of a tree frog into interpretable components. Source: Marco Tulio Ribeiro.
Then we modify the image in a number of ways to enable or disable some of the interpretable components (in the case of this image, the excluded areas are grayed out). For each of the generated images the probability of a tree frog’s presence on it (according to our model) is obtained.
The next step is to learn a linear model weighed locally on the received dataset, so we can understand how it behaves in a small local environment. As the final result of the algorithm (explanation of the original model), the components with the highest weights are presented.
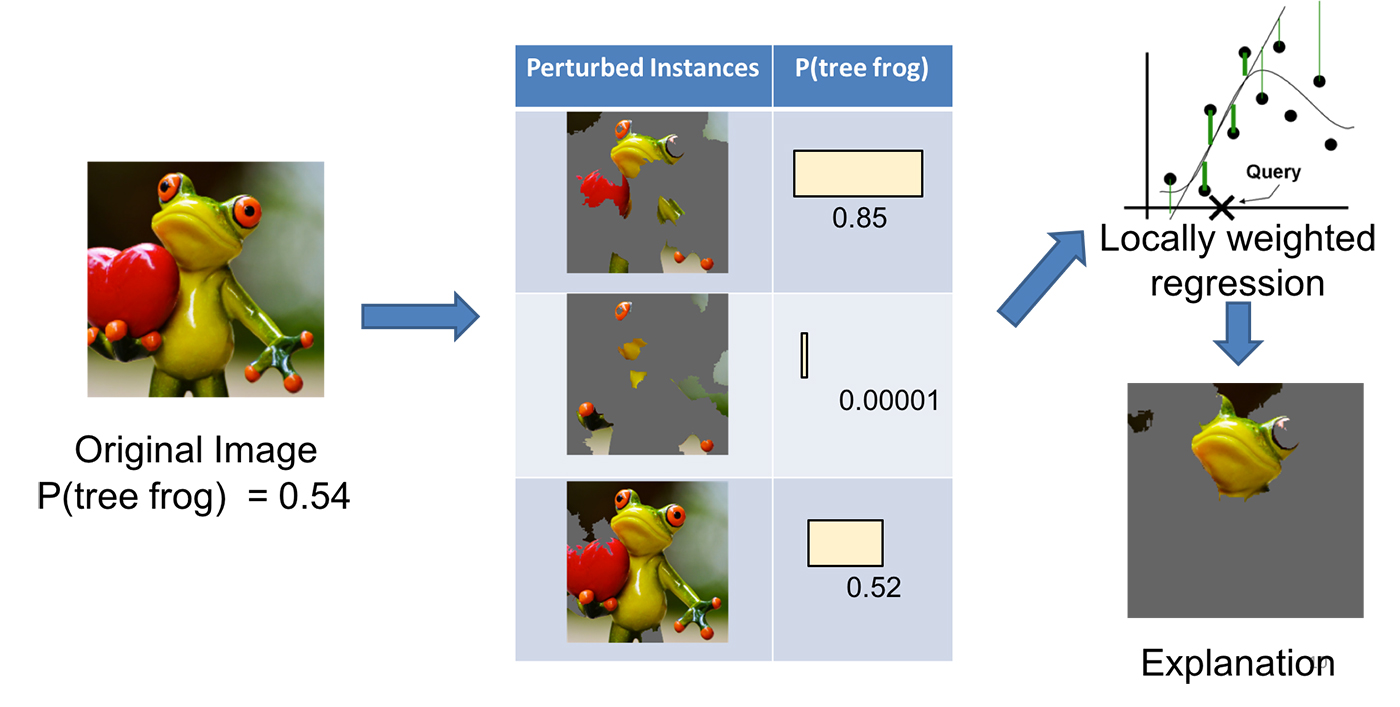
Schematics for generating model explanations using the LIME framework. Source: Marco Tulio Ribeiro.
LIME - use case
20 Newsgroup dataset is a collection of about 20,000 documents divided into 20 topics from discussion groups (e.g. sport, Christianity, atheism or electronics). It is one of the most popular data sets used in natural language processing (NLP).
Let us assume that we have created a classification of random books, which distinguishes which of the two thematic groups (Christianity or atheism) a given text belongs to. Below is a code that can be used to generate explanations for the text.
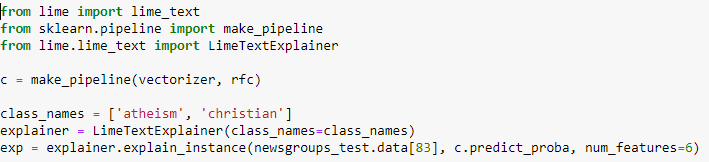
An exemplary text from 20 Newsgroup datasets for which explanations will be generated. Source: Marco Tulio Ribeiro.
A code representing the generation of explanations using LIME. Source: Marco Tulio Ribeiro.
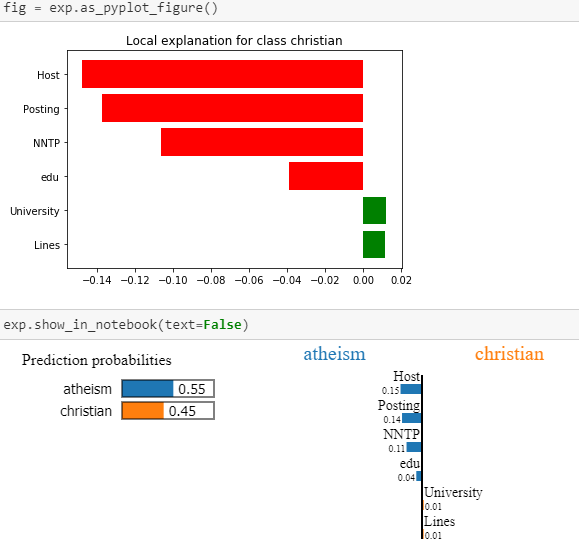
Explanations generated with LIME. Source: Marco Tulio Ribeiro.
It can therefore be seen that, in the case of the above text, the model assumes belonging to the class “atheism” mainly on the basis of words: Host’, ‘Posting’, ‘NNTP’ or ‘edu’.
However, LIME is not the only framework we can use to interpret models. They also include, for example:
- DALEX https://github.com/pbiecek/DALEX
- SHAP https://github.com/slundberg/shap
- ELI5 https://eli5.readthedocs.io/en/latest/
- RandomForestExplainer (R package)
- XgboostExplainer (R package)
Example of application of interpretability of artificial intelligence models and systems in business and science
The interpretability of the models has proven its value in many areas of business and scientific activities, such as:
- Detection of unusual behaviours – identification and explanation of events and unusual behaviours,
- Detection of fraud – to identify and explain why certain transactions are treated as frauds,
- Opinion on loans and credits – identification and explanation of why a certain customer will be able to pay off debt and another will not,
- Marketing campaigns, targeting of advertisements – increasing the accuracy of offers and messages and matching the content to the true and most important interests of merchants,
- Medical diagnostics,
- Automation of vehicles,
- And many others.
Machine learning and artificial intelligence models are used in many areas of our lives, such as medicine, law, transport, finance and security. Considering that they very often have a direct impact on humans, it is very important to understand on what basis they make decisions. A technique that deals with the explanation of complex AI models comes to the assistance then.
")
