Pioneering Progress: Zero-Shot Learning Redefines Image Segmentation

Aleksandra Gontarczyk
AI Engineer
March 8, 2024
Image segmentation, a cornerstone of computer vision, is undergoing a revolutionary transformation with the integration of zero-shot learning (ZSL). Traditionally reliant on extensive labeled datasets, image segmentation faces challenges when encountering new, unknown classes. With the introduction of zero-shot learning to segmentation, this paradigm shift not only expands the horizons of recognition but also navigates uncharted territories. It enables the segmentation of objects in images that belong to classes unseen during training.
The concept of zero-shot learning
Zero-shot learning is an approach that leverages the deductive capabilities of models. Imagine a scenario where a model needs to recognize a million different objects or specific categories. Compiling a comprehensive dataset for training such a model could be incredibly time-consuming.
To address this challenge, researchers have developed an alternative method. During training, they utilize data that includes only a subset of the desired classes. This approach allows the model to generate a high-dimensional vector space that characterizes image features. Models known as image encoders are then used to convert images into vectors that represent these features.
These image encoders are designed to generate a feature vector for any given input image, making it easier to classify unseen categories. Since the model has not been exposed to these classes during its training phase, it relies on auxiliary information about the new categories. This auxiliary information can be in the form of descriptions, word embeddings, or semantic details. When combined with the feature vector produced by the model, this information enables the recognition of new classes.
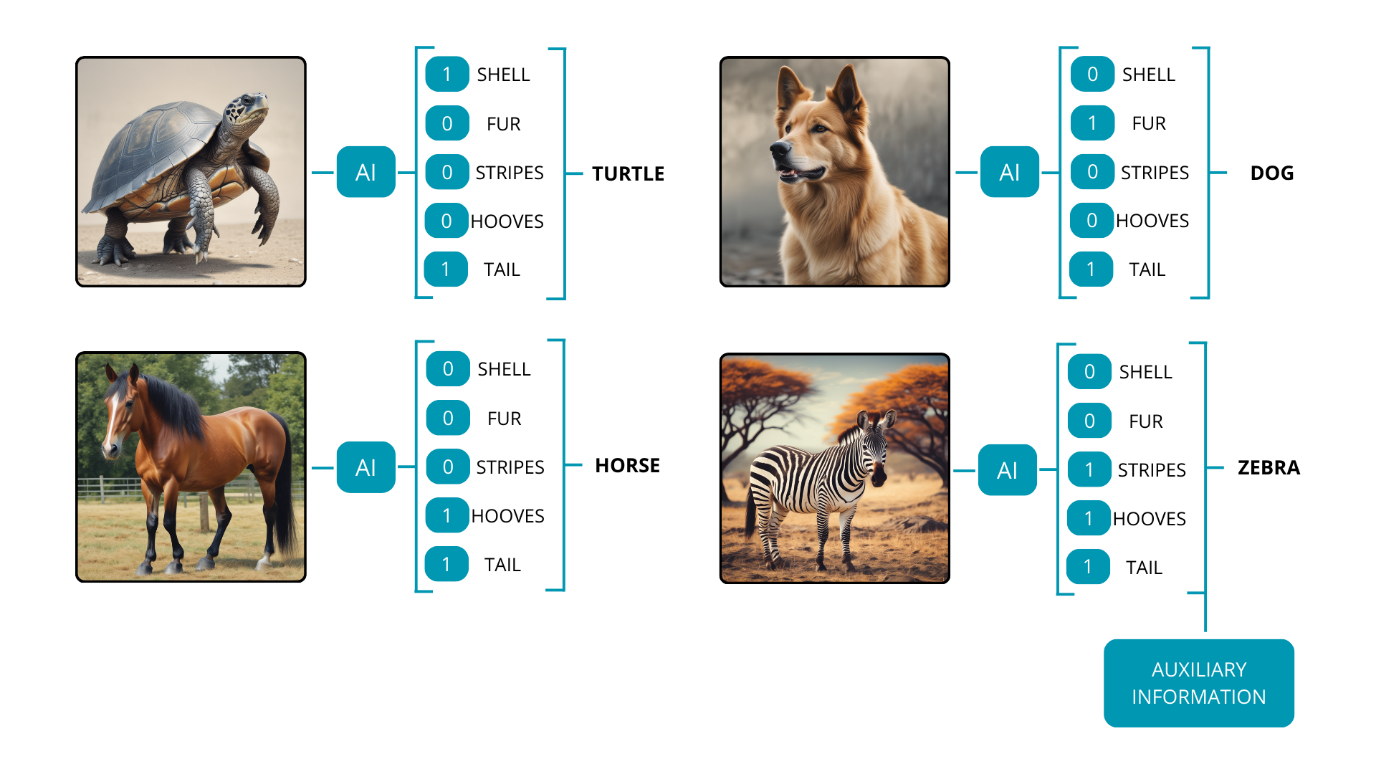
For example, consider a model initially trained on three classes: turtles, dogs, and horses. If we want the model to recognize a new class, such as zebras, we provide it with relevant information that links the new class to those learned during training. A description like ‘Zebra – a horse with black and white stripes’ can be incredibly useful as auxiliary information. With this added knowledge, the model is now equipped to recognize four classes: turtles, dogs, horses, and zebras.
Of course, the zero-shot learning approach varies for different deep learning tasks, including semantic segmentation, object detection, or natural language processing.
Zero-shot learning in semantic segmentation
Semantic segmentation is a computer vision task that involves classifying and labeling each pixel in an image with a specific category or class. Unlike object detection, which typically involves drawing bounding boxes around objects, semantic segmentation provides a more granular understanding of the image by assigning a semantic label to every pixel. The goal is to partition the image into meaningful segments or regions, each corresponding to a particular object or class. The main challenge associated with semantic segmentation is the preparation of data for training, which results in fewer datasets focused on a limited number of classes.
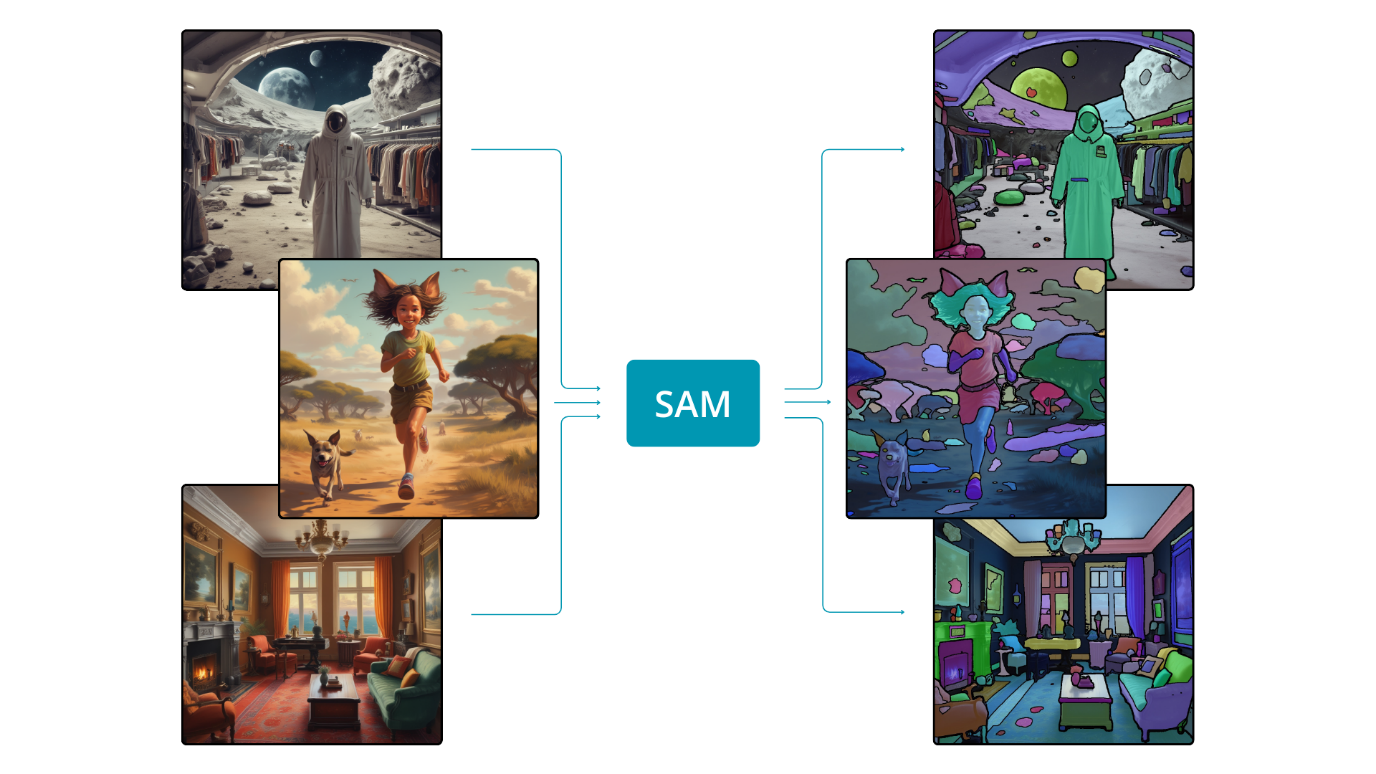
However, perhaps a change in our approach is warranted. Instead of teaching the model the specific appearance of a car and how to extract its mask from an image, we could guide the model in the general skill of extracting any object from an image. This shift is akin to the human ability to identify objects in an image without prior knowledge of their appearance. If the model is adept at distinguishing the pixels belonging to one object from those of others, it can extend its functionality to objects it has not encountered during training – this is the essence of zero-shot learning. A model with this capability, known as the Segment Anything Model (SAM), was introduced some time ago and marked a significant revolution in the field of artificial intelligence.
The Segment Anything Model (SAM) is a promptable semantic segmentation model trained to, as the name suggests, segment anything. To achieve the impressive ability to distinguish any object in an image, the model was trained with over 1 billion segmentation masks. SAM exhibits the proficiency to provide segmentation masks for the entire image and can also generate masks based on prompts, such as specifying boxes or points within the image.
For precise segmentation of a selected object in an image, utilizing a bounding box is instrumental. This method directs the model to focus its segmentation efforts on a specific region of the image.

Another noteworthy feature of SAM is its ability to segment based on a combination of bounding boxes and specified points. This capability is beneficial in scenarios where the goal is to obtain a mask for a particular object without including other objects within the same region.

Segmentation based on text prompt
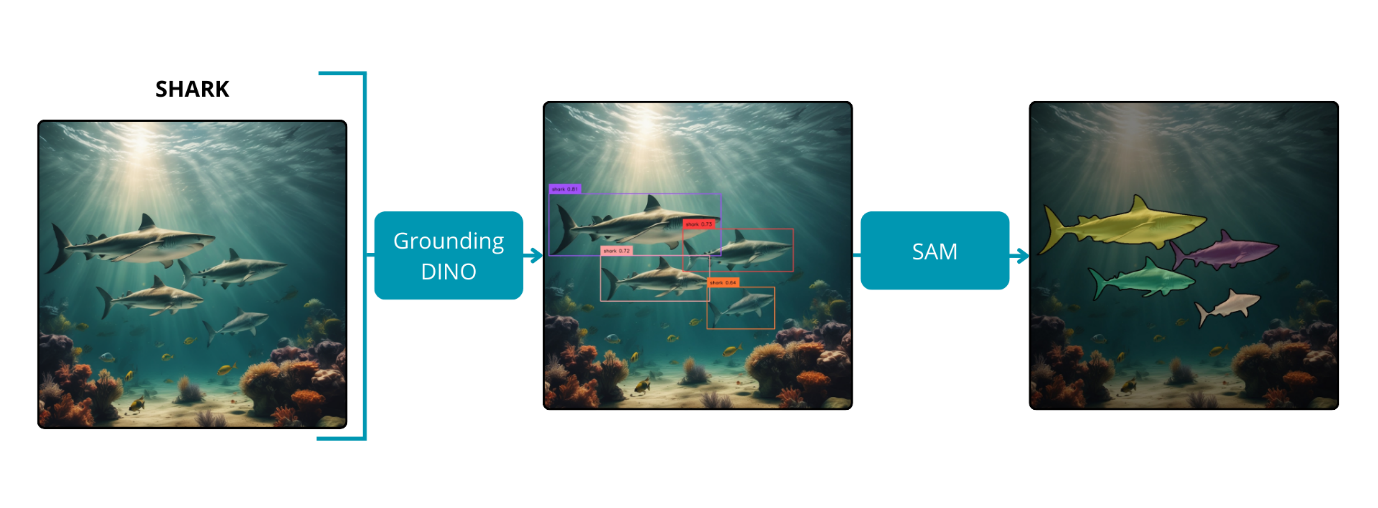
The Segment Anything model has demonstrated commendable results; however, it faces an inherent limitation: the lack of user control and detailed information about the segmented objects. While manipulation through bounding boxes is possible, it requires manual effort to mark the desired objects. Fortunately, a solution addressing this constraint has been developed—Grounded Segment Anything. This innovation represents a synergy between Grounding DINO and the Segment Anything model.
Grounding DINO, a zero-shot object detection model, combines DINO, a transformer-based detection model, with GLIP, an algorithm that unifies object detection and phrase grounding for pre-training. This integration enhances the model’s zero-shot capabilities by interpreting textual input and linking it with corresponding visual representations. Although Grounding DINO exhibits proficient detection skills, its processing speed is too slow for real-time applications. Nonetheless, its utility in automated annotation tasks remains invaluable.
By integrating Grounding DINO with SAM, it becomes possible to derive masks for input images based on any user-provided text. The detection model, guided by textual input, accurately predicts bounding boxes for selected objects. Then, the segmentation model uses these coordinates to generate precise masks. This integrated approach leverages the strengths of both object detection and semantic segmentation, offering enhanced control and interpretability over the segmentation process.
Use Cases
Grounded Segment Anything opens the door to various extensions, from automatic annotation and controllable image editing to prompt-based human motion analysis. This versatile model can seamlessly integrate with various deep learning models and algorithms to achieve tailored functionalities. Numerous notable collaborations have already been established, and undoubtedly, more will continue to emerge in the future.
- RAM Grounded SAM
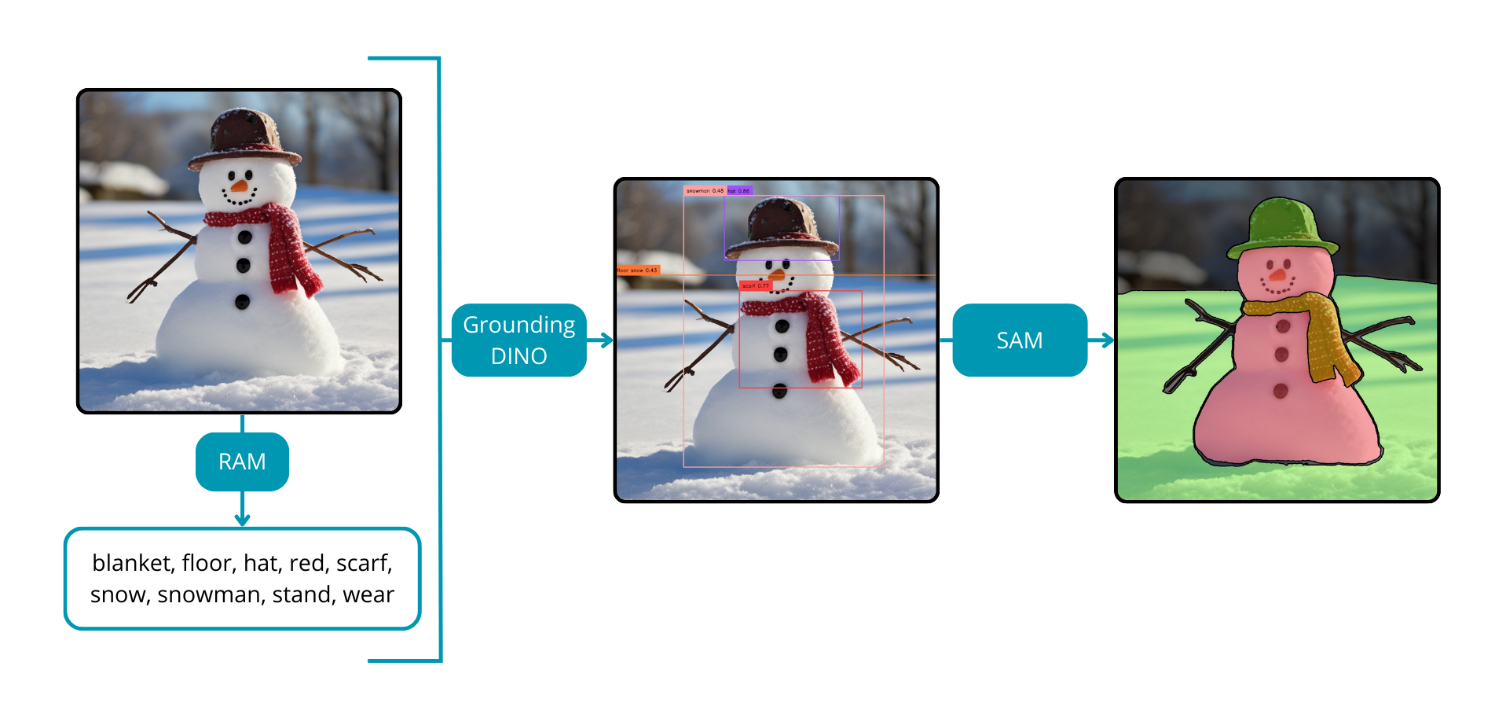
The Recognize Anything Model (RAM) stands out as an image tagging deep learning model endowed with potent zero-shot generalization capabilities. It has the ability to tag input images without the need for bounding boxes or masks. When integrated with Grounded SAM, this synergy results in a comprehensive tool for automatic image annotation.
In the initial stage, RAM efficiently returns tags for the input image. These tags subsequently serve as input for the Grounding DINO model. Finally, with the incorporation of SAM, the process culminates in the generation of masks corresponding to the identified tags. Remarkably, this entire workflow unfolds without any manual intervention, offering a significant reduction in the time and cost associated with image annotation.
The collaborative use of RAM and Grounded SAM not only streamlines the image annotation process but also holds the potential to expedite the development of new artificial intelligence algorithms. By automating the annotation workflow, this integrated approach enhances efficiency and facilitates the seamless integration of advanced machine learning techniques, thereby contributing to the evolution of the broader landscape of artificial intelligence.
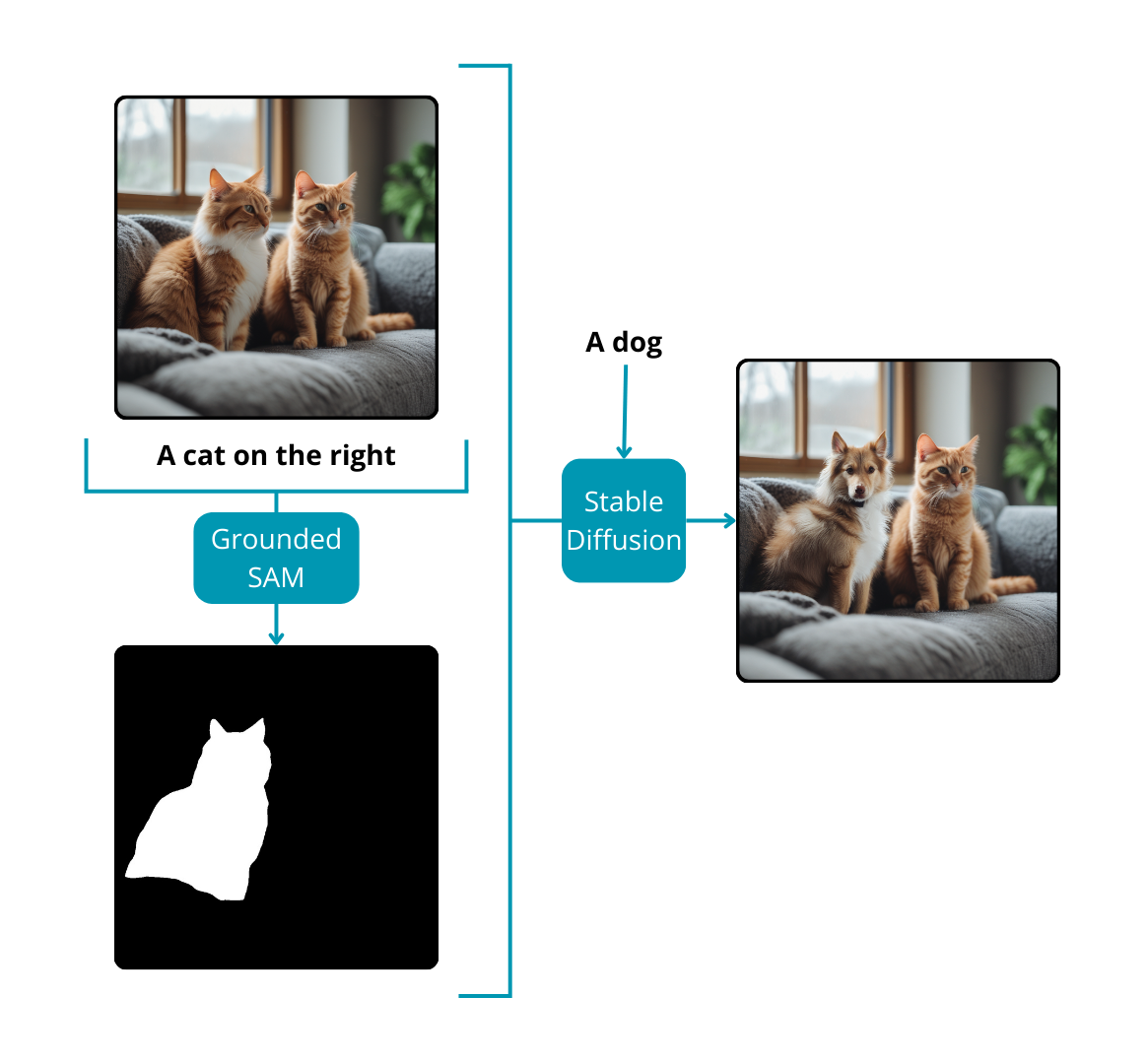
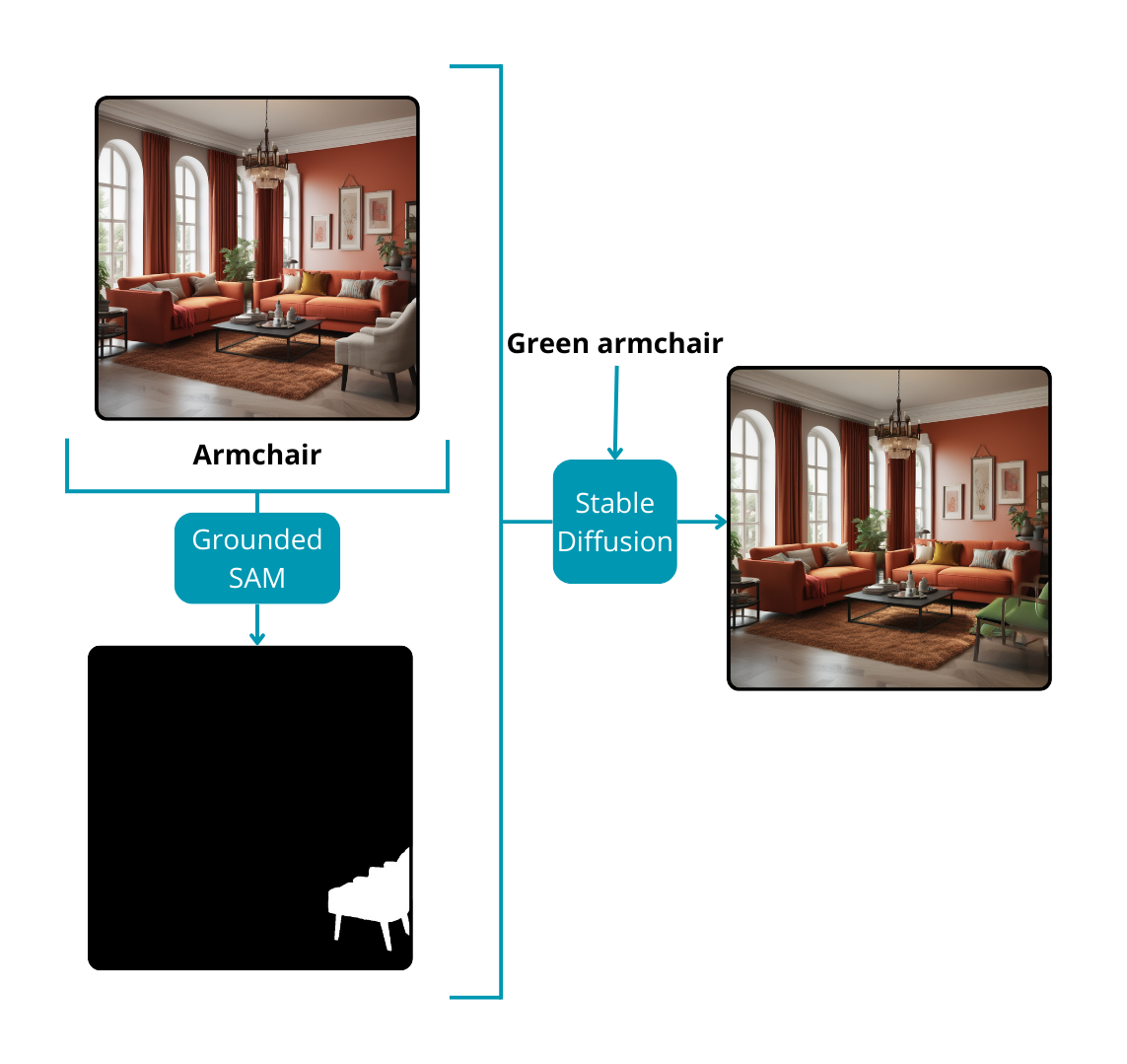
- Grounded SAM and Stable Diffusion model
Stable Diffusion models specialize in generating images based on textual prompts or a combination of text and image inputs to create entirely new compositions. Beyond their creative capacity, these models prove to be valuable tools for image editing, especially in modifying specific regions of an existing image. To guide the model in altering designated parts of an image, a crucial component is required: a mask. This leads to a comprehensive solution for image editing without manual intervention.
The process begins with Grounded SAM, which, based on a text prompt, returns masks for noteworthy instances within the image. Subsequently, the user, armed with another text prompt, instructs the Stable Diffusion model on the desired modifications for the sections of the image marked by the masks. Through this iterative interaction, the final image is seamlessly transformed. This approach is particularly beneficial for inpainting tasks or for effecting changes from one object to another within an image, presenting a versatile and powerful solution for nuanced image editing applications.
For a deeper understanding of Diffusion Models and their broader implications in the field of artificial intelligence, consider exploring our detailed article here: Read More
Summary
Despite its potential, zero-shot learning in segmentation encounters challenges, including handling fine details in unseen classes and ensuring robustness against semantic variations. Additionally, inferencing time remains an issue, as current zero-shot segmentation models are too slow for real-time applications. As the research community continues to explore these challenges, the future holds exciting possibilities for refining and expanding the capabilities of zero-shot learning in image segmentation.
Seamless Image Segmentation: Custom Zero-Shot Learning Solutions by theBlue.ai
At theBlue.ai, we specialize in custom AI solutions tailored to the unique needs of our clients. Navigating the complexities of zero-shot learning in image segmentation, we overcome challenges like fine detail handling, semantic robustness, and real-time application speeds. Partner with us to transform these advanced technologies into practical solutions for your business, driving innovation and efficiency. Discover the difference with us, feel free to contact us.
")