Bahnbrechender Fortschritt: Zero-Shot-Learning definiert Bildsegmentierung neu

Aleksandra Gontarczyk
AI Engineer
8 März 2024
Bildsegmentierung, ein Grundpfeiler der Computer Vision, erfährt durch die Integration von Zero-Shot-Learning (ZSL) eine revolutionäre Verwandlung. Traditionell auf umfangreiche, beschriftete Datensätze angewiesen, sieht sich die Bildsegmentierung Herausforderungen gegenüber, wenn sie auf neue, unbekannte Klassen trifft. Mit der Einführung von Zero-Shot-Learning in die Segmentierung erweitert dieser Paradigmenwechsel nicht nur den Horizont der Erkennung, sondern erkundet auch unbekanntes Terrain. Es ermöglicht die Segmentierung von Objekten in Bildern, die zu Klassen gehören, die während des Trainings nicht gesehen wurden.
Das Konzept des Zero-Shot-Learnings
Zero-Shot-Learning ist ein Ansatz, der die deduktiven Fähigkeiten von Modellen nutzt. Stellen Sie sich ein Szenario vor, in dem ein Modell eine Million verschiedene Objekte oder spezifische Kategorien erkennen muss. Die Zusammenstellung eines umfassenden Datensatzes für das Training eines solchen Modells könnte unglaublich zeitaufwendig sein.
Um diese Herausforderung zu bewältigen, haben Forscher eine alternative Methode entwickelt. Während des Trainings nutzen sie Daten, die nur eine Teilmenge der gewünschten Klassen enthalten. Dieser Ansatz ermöglicht es dem Modell, einen hochdimensionalen Vektorraum zu generieren, der Bildmerkmale charakterisiert. Modelle, die als Bildkodierer bekannt sind, werden dann verwendet, um Bilder in Vektoren umzuwandeln, die diese Merkmale repräsentieren.
Diese Bildkodierer sind darauf ausgelegt, für jedes gegebene Eingabebild einen Merkmalsvektor zu erzeugen, was die Klassifizierung unbekannter Kategorien erleichtert. Da das Modell während seiner Trainingsphase diesen Klassen nicht ausgesetzt war, stützt es sich auf zusätzliche Informationen über die neuen Kategorien. Diese zusätzlichen Informationen können in Form von Beschreibungen, Wort-Einbettungen oder semantischen Details vorliegen. Kombiniert mit dem vom Modell erzeugten Merkmalsvektor ermöglicht diese Information die Erkennung neuer Klassen.
Betrachten Sie zum Beispiel ein Modell, das ursprünglich auf drei Klassen trainiert wurde: Schildkröten, Hunde und Pferde. Wenn wir möchten, dass das Modell eine neue Klasse wie Zebras erkennt, geben wir ihm relevante Informationen, die die neue Klasse mit denen in Verbindung setzen, die während des Trainings gelernt wurden. Eine Beschreibung wie ‘Zebra – ein Pferd mit schwarz-weißen Streifen’ kann als zusätzliche Information unglaublich nützlich sein. Mit diesem zusätzlichen Wissen ist das Modell nun in der Lage, vier Klassen zu erkennen: Schildkröten, Hunde, Pferde und Zebras.
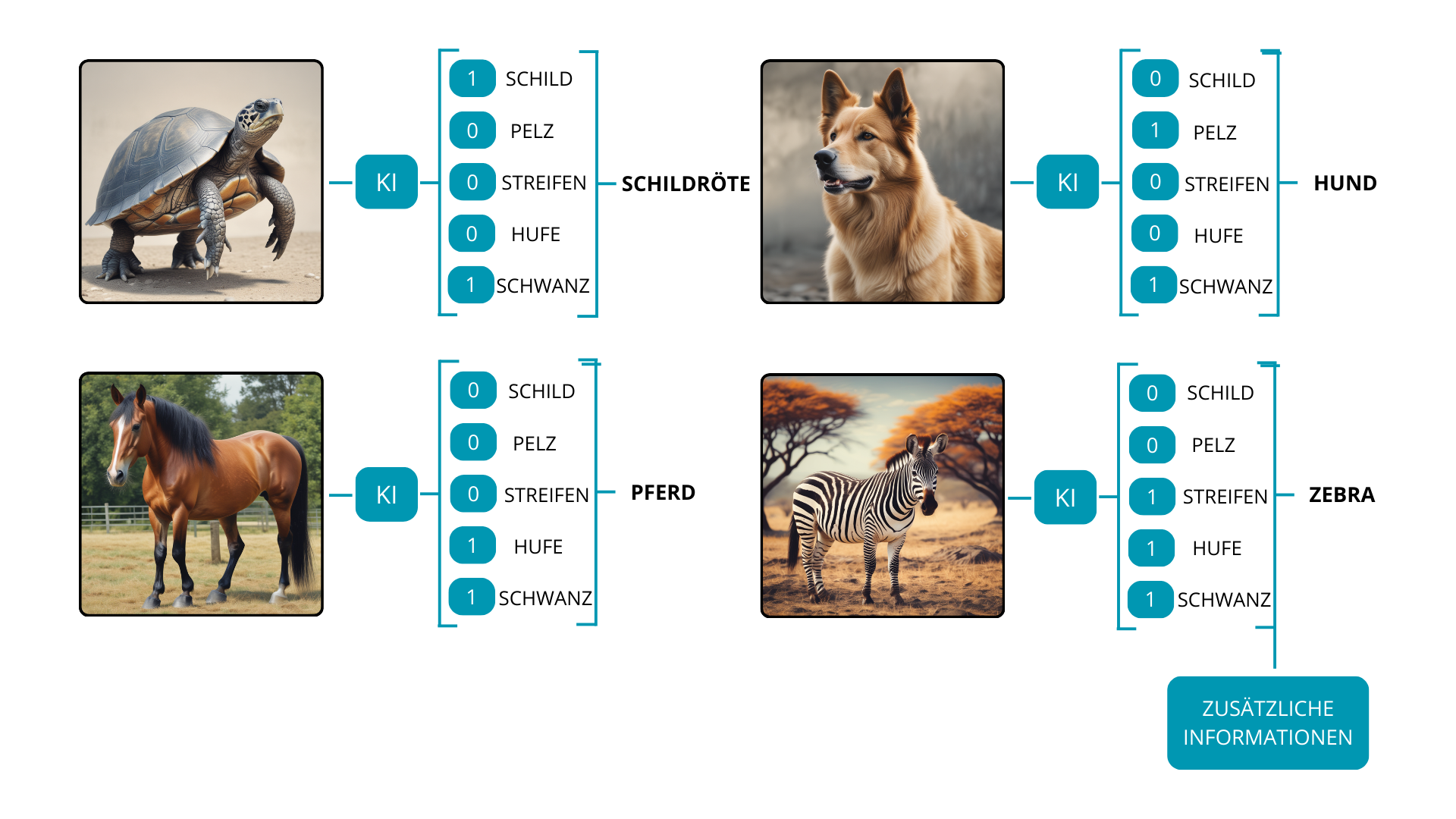
Natürlich variiert der Zero-Shot-Learning-Ansatz für verschiedene Deep-Learning-Aufgaben, einschließlich semantischer Segmentierung, Objekterkennung oder Verarbeitung natürlicher Sprache.
Zero-Shot-Learning in der semantischen Segmentierung
Die Semantische Segmentierung ist eine Aufgabe der Computer Vision, die darin besteht, jeden Pixel eines Bildes mit einer spezifischen Kategorie oder Klasse zu klassifizieren und zu kennzeichnen. Im Gegensatz zur Objekterkennung, die typischerweise das Zeichnen von Begrenzungsrahmen um Objekte beinhaltet, bietet die semantische Segmentierung durch die Zuweisung eines semantischen Labels zu jedem Pixel ein detaillierteres Verständnis des Bildes. Ziel ist es, das Bild in sinnvolle Segmente oder Bereiche zu unterteilen, die jeweils einem bestimmten Objekt oder einer Klasse entsprechen. Die Hauptherausforderung bei der semantischen Segmentierung ist die Vorbereitung der Daten für das Training, was zu weniger Datensätzen führt, die sich auf eine begrenzte Anzahl von Klassen konzentrieren.
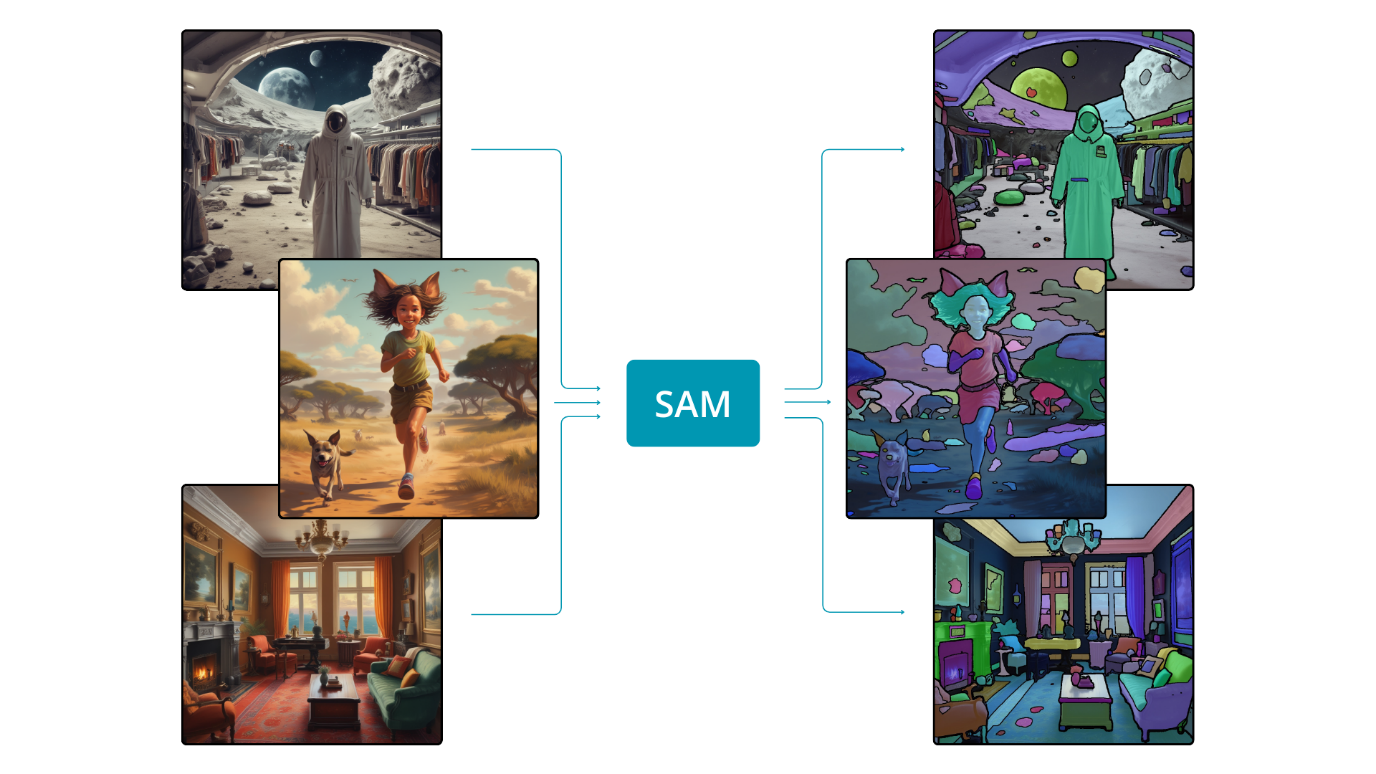
Vielleicht ist jedoch eine Änderung unseres Ansatzes angebracht. Anstatt dem Modell das spezifische Aussehen eines Autos beizubringen und wie es dessen Maske aus einem Bild extrahieren kann, könnten wir das Modell in der allgemeinen Fähigkeit schulen, jedes Objekt aus einem Bild zu extrahieren. Diese Verschiebung ähnelt der menschlichen Fähigkeit, Objekte in einem Bild zu identifizieren, ohne vorheriges Wissen über ihr Aussehen. Wenn das Modell geschickt darin ist, die Pixel, die zu einem Objekt gehören, von denen anderer Objekte zu unterscheiden, kann es seine Funktionalität auf Objekte ausweiten, denen es während des Trainings nicht begegnet ist – dies ist das Wesen des Zero-Shot-Learnings. Ein Modell mit dieser Fähigkeit, bekannt als das “Segment Anything Model” (SAM), wurde vor einiger Zeit eingeführt und markierte eine bedeutende Revolution im Bereich der künstlichen Intelligenz.
Das “Segment Anything Model” (SAM) ist ein aufforderbares Modell zur semantischen Segmentierung, das darauf trainiert wurde, wie der Name schon sagt, alles zu segmentieren. Um die beeindruckende Fähigkeit zu erreichen, jedes Objekt in einem Bild zu unterscheiden, wurde das Modell mit über 1 Milliarde Segmentierungsmasken trainiert. SAM zeigt die Fähigkeit, Segmentierungsmasken für das gesamte Bild zu liefern, und kann auch Masken basierend auf Aufforderungen generieren, wie z.B. das Spezifizieren von Boxen oder Punkten innerhalb des Bildes.
Für eine präzise Segmentierung eines ausgewählten Objekts in einem Bild ist die Verwendung eines Begrenzungsrahmens von entscheidender Bedeutung. Diese Methode leitet das Modell an, seine Segmentierungsbemühungen auf einen spezifischen Bereich des Bildes zu konzentrieren.

Eine weitere bemerkenswerte Eigenschaft von SAM ist seine Fähigkeit, basierend auf einer Kombination aus Begrenzungsrahmen und spezifizierten Punkten zu segmentieren. Diese Fähigkeit ist in Szenarien nützlich, in denen das Ziel darin besteht, eine Maske für ein bestimmtes Objekt zu erhalten, ohne andere Objekte innerhalb desselben Bereichs einzubeziehen.

Segmentierung basierend auf Textaufforderungen
Das Segment Anything-Modell hat lobenswerte Ergebnisse erzielt; es sieht sich jedoch einer inhärenten Einschränkung gegenüber: dem Mangel an Benutzerkontrolle und detaillierten Informationen über die segmentierten Objekte. Obwohl eine Manipulation durch Begrenzungsrahmen möglich ist, erfordert dies manuelle Anstrengungen, um die gewünschten Objekte zu markieren. Glücklicherweise wurde eine Lösung für diese Einschränkung entwickelt – Grounded Segment Anything. Diese Innovation repräsentiert eine Synergie zwischen Grounding DINO und dem Segment Anything-Modell.
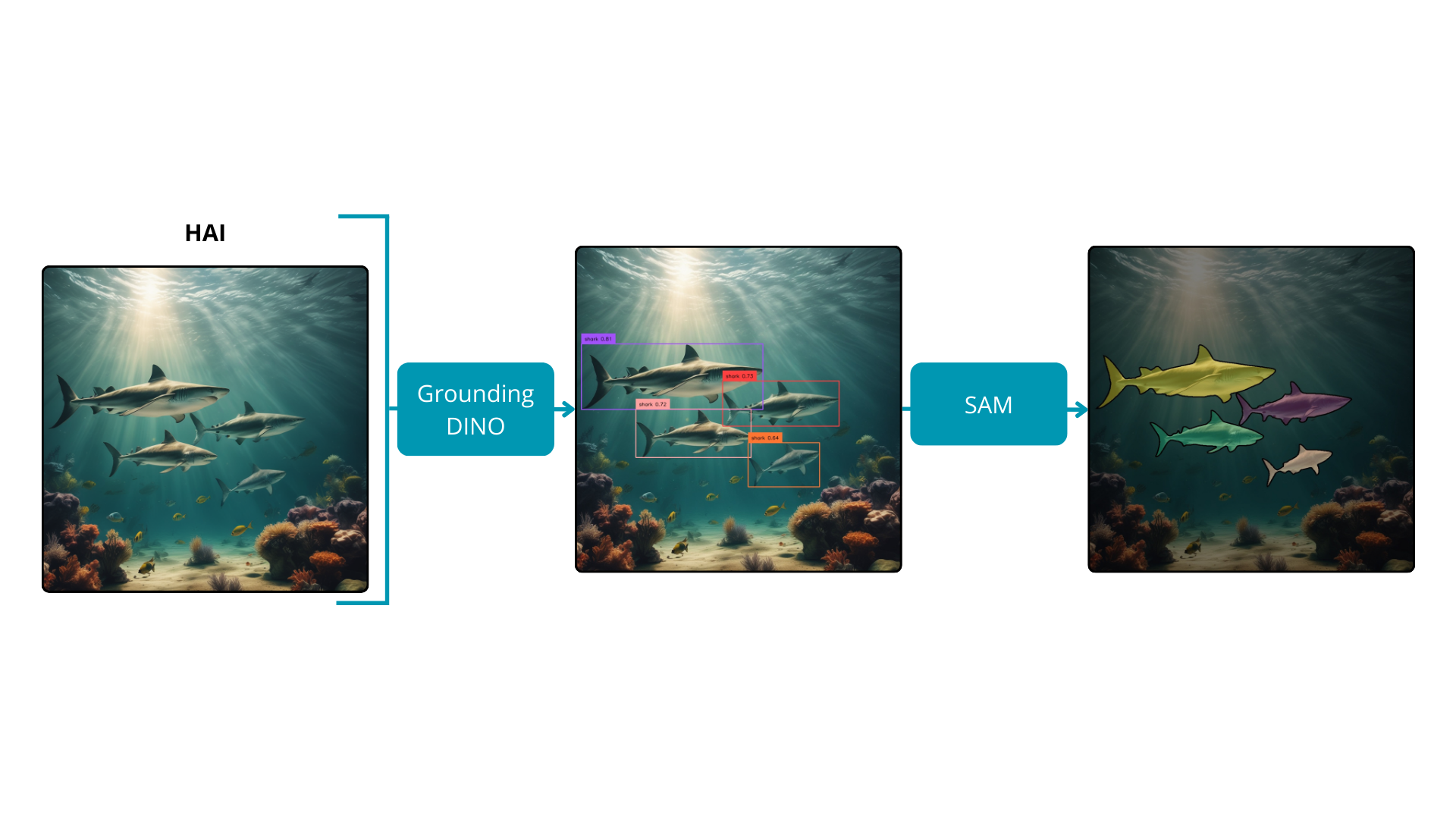
Grounding DINO, ein Zero-Shot-Objekterkennungsmodell, kombiniert DINO, ein auf einem Transformer basierendes Erkennungsmodell, mit GLIP, einem Algorithmus, der Objekterkennung und Phrasen-Verankerung für das Pre-Training vereint. Diese Integration verbessert die Zero-Shot-Fähigkeiten des Modells, indem sie textuelle Eingaben interpretiert und diese mit entsprechenden visuellen Darstellungen verknüpft. Obwohl Grounding DINO überzeugende Erkennungsfähigkeiten zeigt, ist seine Verarbeitungsgeschwindigkeit für Echtzeitanwendungen zu langsam. Dennoch bleibt sein Nutzen in automatisierten Annotationstasks unbezahlbar.
Durch die Integration von Grounding DINO mit SAM wird es möglich, Masken für Eingabebilder basierend auf jedem vom Benutzer bereitgestellten Text abzuleiten. Das Erkennungsmodell, geleitet von textuellen Eingaben, sagt genau die Begrenzungsrahmen für ausgewählte Objekte voraus. Anschließend verwendet das Segmentierungsmodell diese Koordinaten, um präzise Masken zu generieren. Dieser integrierte Ansatz nutzt die Stärken sowohl der Objekterkennung als auch der semantischen Segmentierung und bietet eine verbesserte Kontrolle und Interpretierbarkeit über den Segmentierungsprozess.
Use Cases
Grounded Segment Anything eröffnet die Tür zu verschiedenen Erweiterungen, von automatischer Annotation und kontrollierbarer Bildbearbeitung bis hin zu promptbasierter Analyse menschlicher Bewegungen. Dieses vielseitige Modell kann nahtlos mit verschiedenen Deep-Learning-Modellen und Algorithmen integriert werden, um maßgeschneiderte Funktionalitäten zu erreichen. Zahlreiche bemerkenswerte Kooperationen wurden bereits etabliert und zweifellos werden in Zukunft weitere entstehen.
- RAM Grounded SAM
Das Recognize Anything Model (RAM) zeichnet sich als ein Deep-Learning-Modell zur Bildkennzeichnung aus, das mit starken Zero-Shot-Generalisierungsfähigkeiten ausgestattet ist. Es hat die Fähigkeit, Eingabebilder zu kennzeichnen, ohne dass Begrenzungsrahmen oder Masken erforderlich sind. In Kombination mit Grounded SAM führt diese Synergie zu einem umfassenden Werkzeug für die automatische Bildannotation.
In der Anfangsphase liefert RAM effizient Tags für das Eingabebild. Diese Tags dienen anschließend als Eingabe für das Grounding DINO-Modell. Schließlich führt die Einbindung von SAM zum Abschluss des Prozesses in der Generierung von Masken, die den identifizierten Tags entsprechen. Bemerkenswerterweise entfaltet sich dieser gesamte Workflow ohne manuelle Eingriffe, was eine erhebliche Reduzierung der Zeit und Kosten im Zusammenhang mit der Bildannotation bietet.
Die gemeinsame Nutzung von RAM und Grounded SAM vereinfacht nicht nur den Prozess der Bildannotation, sondern birgt auch das Potenzial, die Entwicklung neuer künstlicher Intelligenz-Algorithmen zu beschleunigen. Indem der Annotationsworkflow automatisiert wird, verbessert dieser integrierte Ansatz die Effizienz und erleichtert die nahtlose Integration fortschrittlicher maschineller Lernverfahren und trägt so zur Entwicklung der breiteren Landschaft der künstlichen Intelligenz bei.

- Grounded SAM und das Stable Diffusion-Modell
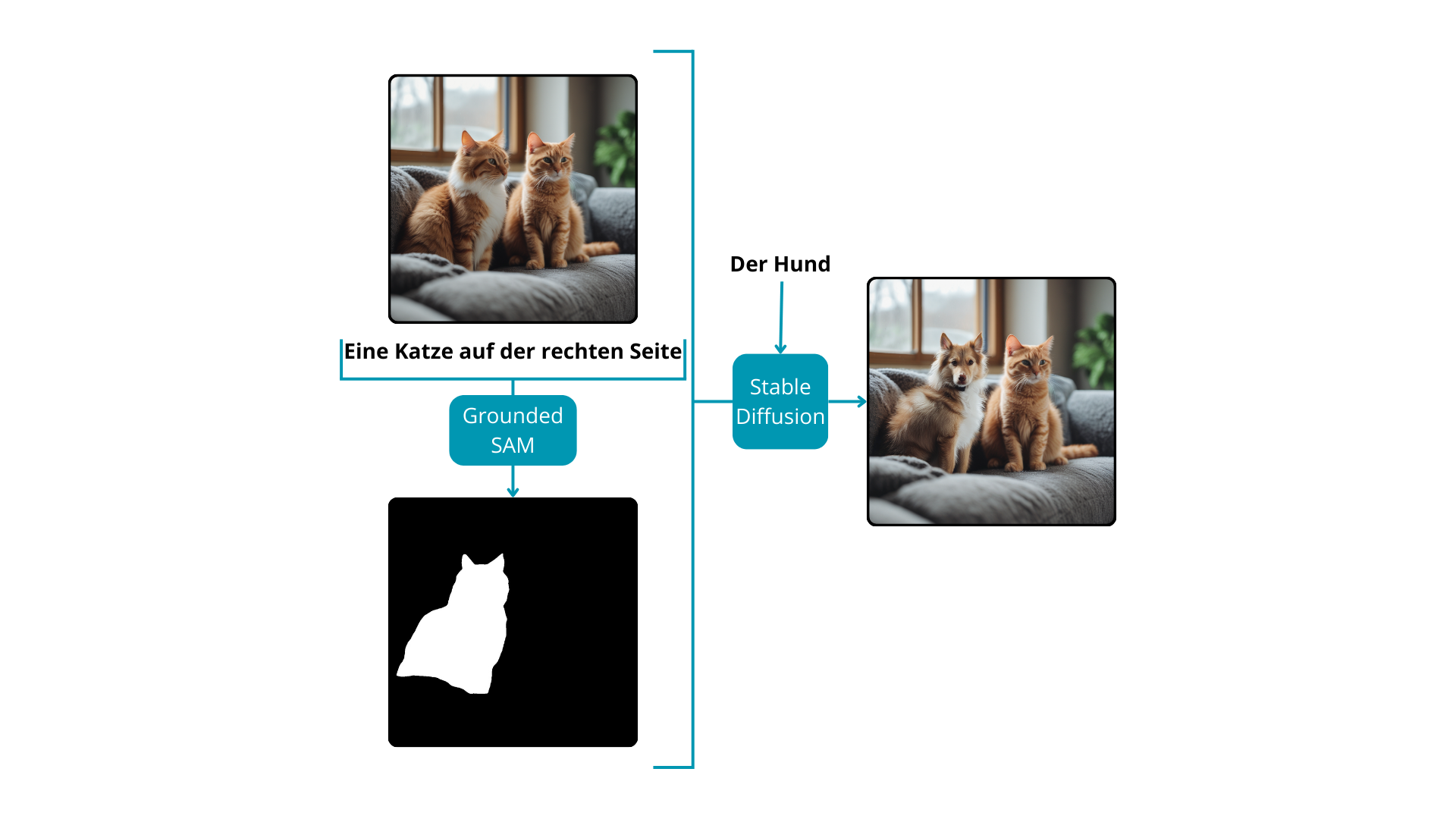
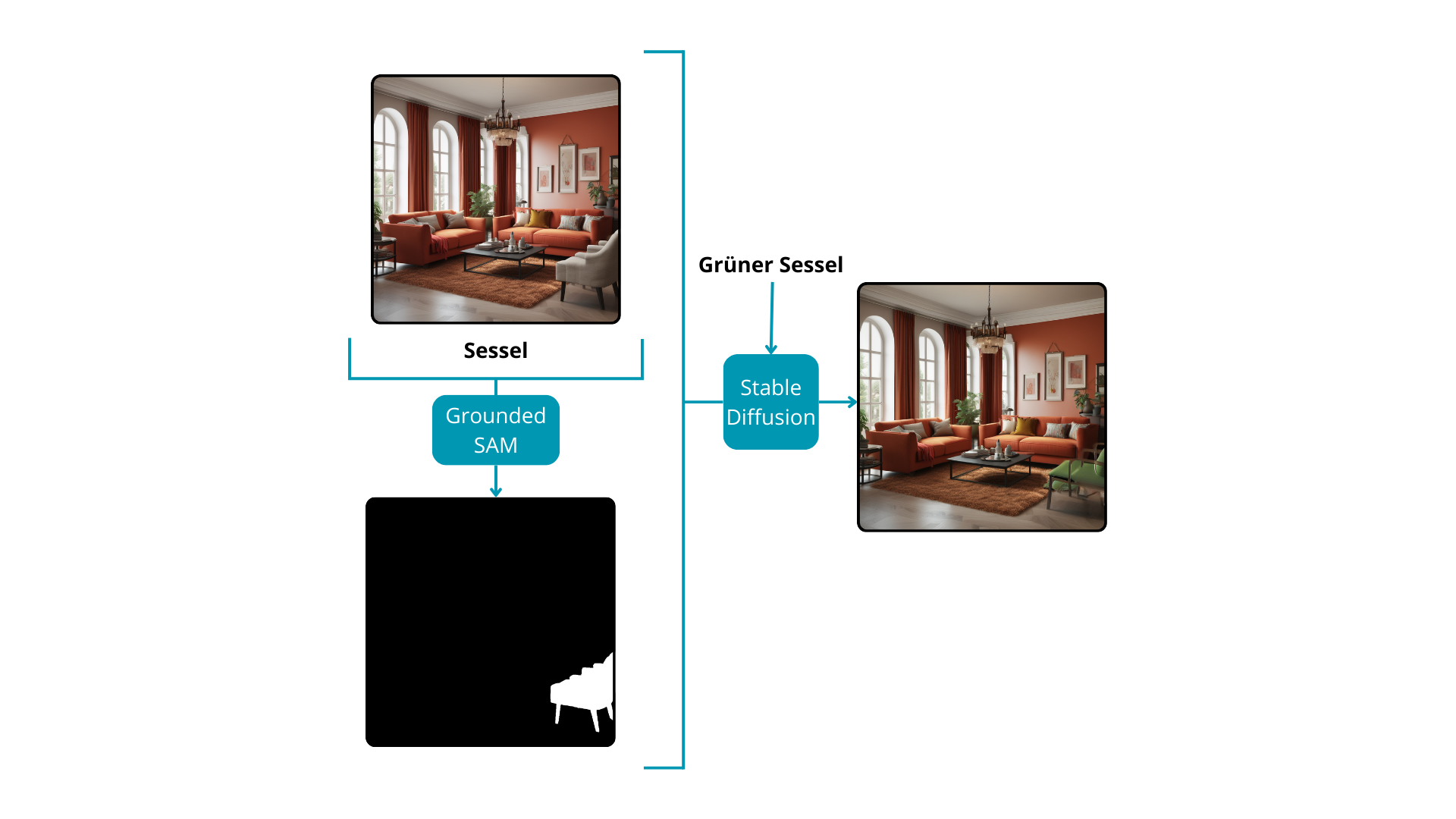
Stable Diffusion-Modelle sind darauf spezialisiert, Bilder basierend auf Textaufforderungen oder einer Kombination aus Text- und Bildeingaben zu generieren, um völlig neue Kompositionen zu erstellen. Über ihre kreative Kapazität hinaus erweisen sich diese Modelle als wertvolle Werkzeuge für die Bildbearbeitung, insbesondere bei der Modifizierung spezifischer Bereiche eines vorhandenen Bildes. Um das Modell bei der Änderung bestimmter Teile eines Bildes zu leiten, ist eine entscheidende Komponente erforderlich: eine Maske. Dies führt zu einer umfassenden Lösung für die Bildbearbeitung ohne manuelle Eingriffe.
Der Prozess beginnt mit Grounded SAM, das basierend auf einer Textaufforderung Masken für bemerkenswerte Instanzen innerhalb des Bildes zurückgibt. Anschließend gibt der Benutzer mit einer weiteren Textaufforderung Anweisungen an das Stable Diffusion-Modell bezüglich der gewünschten Änderungen für die durch die Masken markierten Abschnitte des Bildes. Durch diese iterative Interaktion wird das Endbild nahtlos transformiert. Dieser Ansatz ist besonders vorteilhaft für Inpainting-Aufgaben oder für Änderungen von einem Objekt zu einem anderen innerhalb eines Bildes und bietet eine vielseitige und leistungsstarke Lösung für nuancierte Bildbearbeitungsanwendungen.
Für ein tieferes Verständnis von Diffusionsmodellen und deren breiteren Auswirkungen im Bereich der künstlichen Intelligenz, erwägen Sie, unseren detaillierten Artikel hier zu erkunden: Mehr erfahren
Zusammenfassung
Trotz seines Potenzials stößt Zero-Shot-Learning in der Segmentierung auf Herausforderungen, einschließlich der Handhabung feiner Details bei unbekannten Klassen und der Gewährleistung von Robustheit gegenüber semantischen Variationen. Zusätzlich bleibt die Inferenzzeit ein Problem, da aktuelle Modelle für Zero-Shot-Segmentierung zu langsam für Echtzeitanwendungen sind. Während die Forschungsgemeinschaft diese Herausforderungen weiter erforscht, halten die Zukunft spannende Möglichkeiten bereit, um die Fähigkeiten von Zero-Shot-Learning in der Bildsegmentierung zu verfeinern und zu erweitern.
Nahtlose Bildsegmentierung: Individuelle Zero-Shot-Learning-Lösungen von theBlue.ai
Bei theBlue.ai sind wir auf maßgeschneiderte KI-Lösungen spezialisiert, die auf die einzigartigen Bedürfnisse unserer Kunden zugeschnitten sind. Wir navigieren durch die Komplexitäten des Zero-Shot-Learnings in der Bildsegmentierung und überwinden Herausforderungen wie die Handhabung feiner Details, semantische Robustheit und Geschwindigkeiten für Echtzeitanwendungen. Arbeiten Sie mit uns zusammen, um diese fortschrittlichen Technologien in praktische Lösungen für Ihr Unternehmen zu verwandeln, die Innovation und Effizienz vorantreiben. Zögern Sie nicht, uns zu kontaktieren, um über Ihre Projektidee zu sprechen.
")