Pionierski postęp: uczenie zero-shot na nowo definiuje segmentację obrazu

Aleksandra Gontarczyk
AI Engineer
8 marca 2024
Segmentacja obrazu, kamień węgielny wizji komputerowej, przechodzi rewolucyjną transformację wraz z integracją z podejściem uczenia zero-shot. Tradycyjnie oparta na rozbudowanych, oznaczonych zbiorach danych, segmentacja obrazu napotyka problemy, gdy spotyka dane należące do nowych, nieznanych kategorii. Wraz z wprowadzeniem podejścia uczenia zero-shot do segmentacji, rozszerzamy nie tylko zakres rozpoznawania, ale również możemy poruszać się po niezbadanych wcześniej obszarach. To pozwala na segmentację obiektów na obrazie, które należą do klas niewidzianych wcześniej w trakcie treningu.
Koncepcja uczenia zero-shot
Uczenie zero-shot jest podejściem, które opiera się na umiejętnościach dedukcyjnych modeli. Wyobraźmy sobie scenariusz, w którym model musi rozpoznać milion różnych obiektów lub specyficznych kategorii. Przygotowanie kompleksowego zbioru danych do treningu takiego modelu może być niezwykle czasochłonne.
Aby sprostać temu wyzwaniu, badacze opracowali alternatywną metodę. W trakcie treningu, wykorzystują dane, które reprezentują jedynie podzbiór pożądanych klas. Takie podejście pozwala modelowi wygenerować wielowymiarową przestrzeń wektorową opisującą cechy obrazu. Następnie taki model, zwany enkoderem obrazu, jest wykorzystywany do konwertowania obrazów na wektory reprezentujące ich cechy.
Enkodery obrazu są zaprojektowane do generowania wektora cech dla dowolnego otrzymanego obrazu, co ułatwia wykorzystanie ich do klasyfikacji nowych kategorii. Ponieważ model nie miał kontaktu z tymi klasami w fazie uczenia, musi opierać się na informacjach dodatkowych na temat nowych kategorii. Dodatkowe informacje mogą mieć formę opisów, zagnieżdżonych słów lub szczegółów semantycznych. W połączeniu z wektorem cech utworzonym przez model, informacje te umożliwiają rozpoznanie nowych klas.
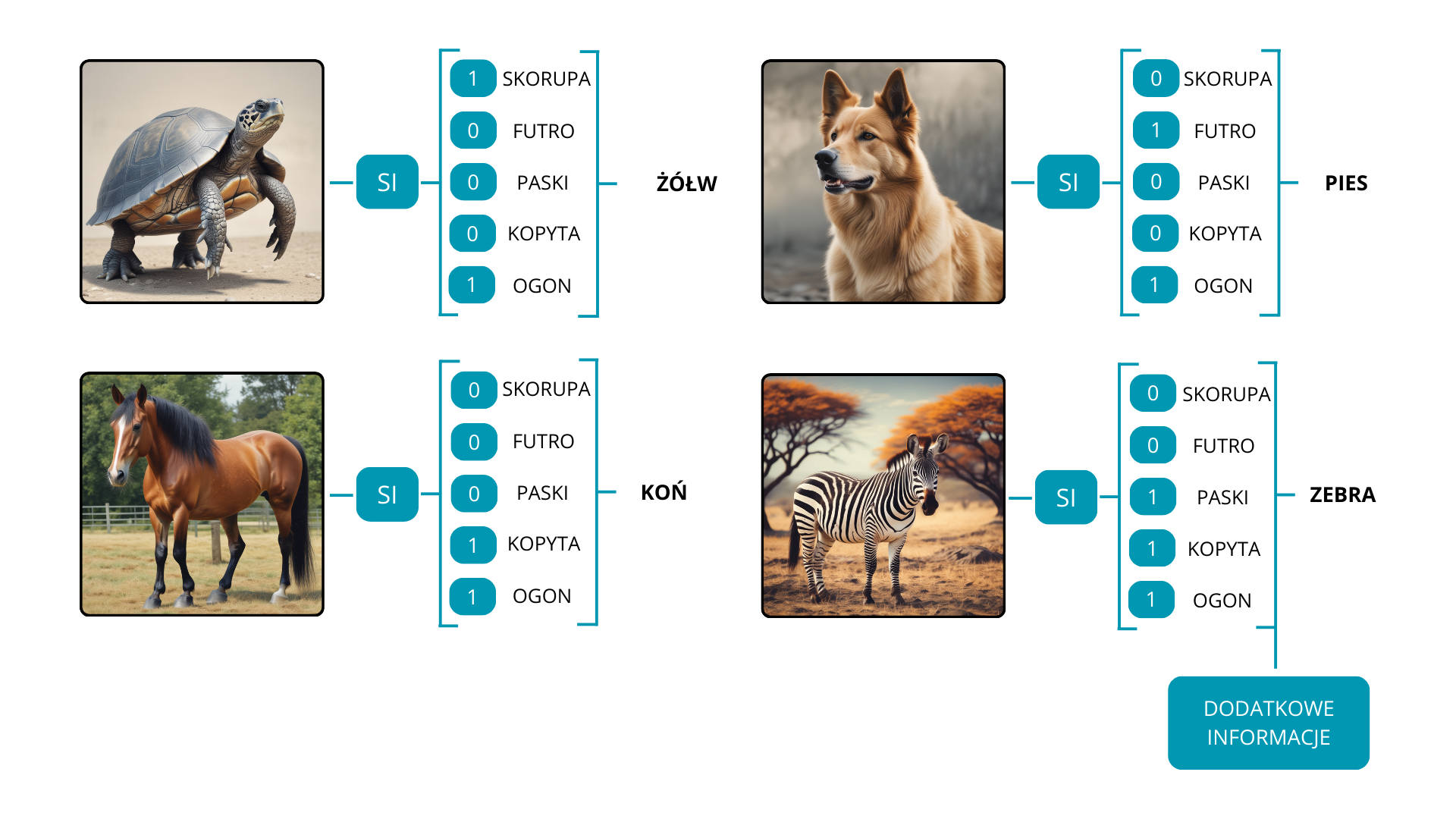
Dla przykładu, rozważmy model początkowo wytrenowany na trzech klasach: żółw, pies i koń. Gdybyśmy chcieli, aby model rozpoznał nową kategorię, taką jak zebra, musimy dostarczyć mu odpowiednie informacje, które w pewien sposób łączą nową klasę z tymi nauczonymi podczas treningu. Opis taki jak “Zebra – koń w czarno-białe paski” będzie niezwykle przydatny jako informacja pomocnicza. Z tą dodatkową wiedzą model jest teraz w stanie rozpoznać cztery kategorie: żółw, pies, koń i zebra.
Oczywiście uczenie zero-shot różni się dla różnych zadań głębokiego uczenia, takich jak segmentacja semantyczna, detekcja obiektów czy przetwarzanie języka naturalnego.
Uczenie zero-shot w segmentacji semantycznej
Segmentacja semantyczna należy do zadań wizji komputerowej, która polega na klasyfikacji i oznaczaniu każdego piksela na obrazie określoną kategorią lub klasą. W przeciwieństwie do wykrywania obiektów, które zazwyczaj obejmuje rysowanie ramek ograniczających wokół obiektów, segmentacja semantyczna zapewnia bardziej szczegółowe rozumienie obrazu poprzez przypisanie etykiety semantycznej do każdego piksela. Celem jest podzielenie obrazu na istotne segmenty lub regiony, które odpowiadają danym obiektom lub klasom. Głównym wyzwaniem związanym z segmentacją semantyczną jest przygotowanie danych do uczenia, co skutkuje mniejszą liczbą zbiorów danych skoncentrowanych na ograniczonej liczbie klas.
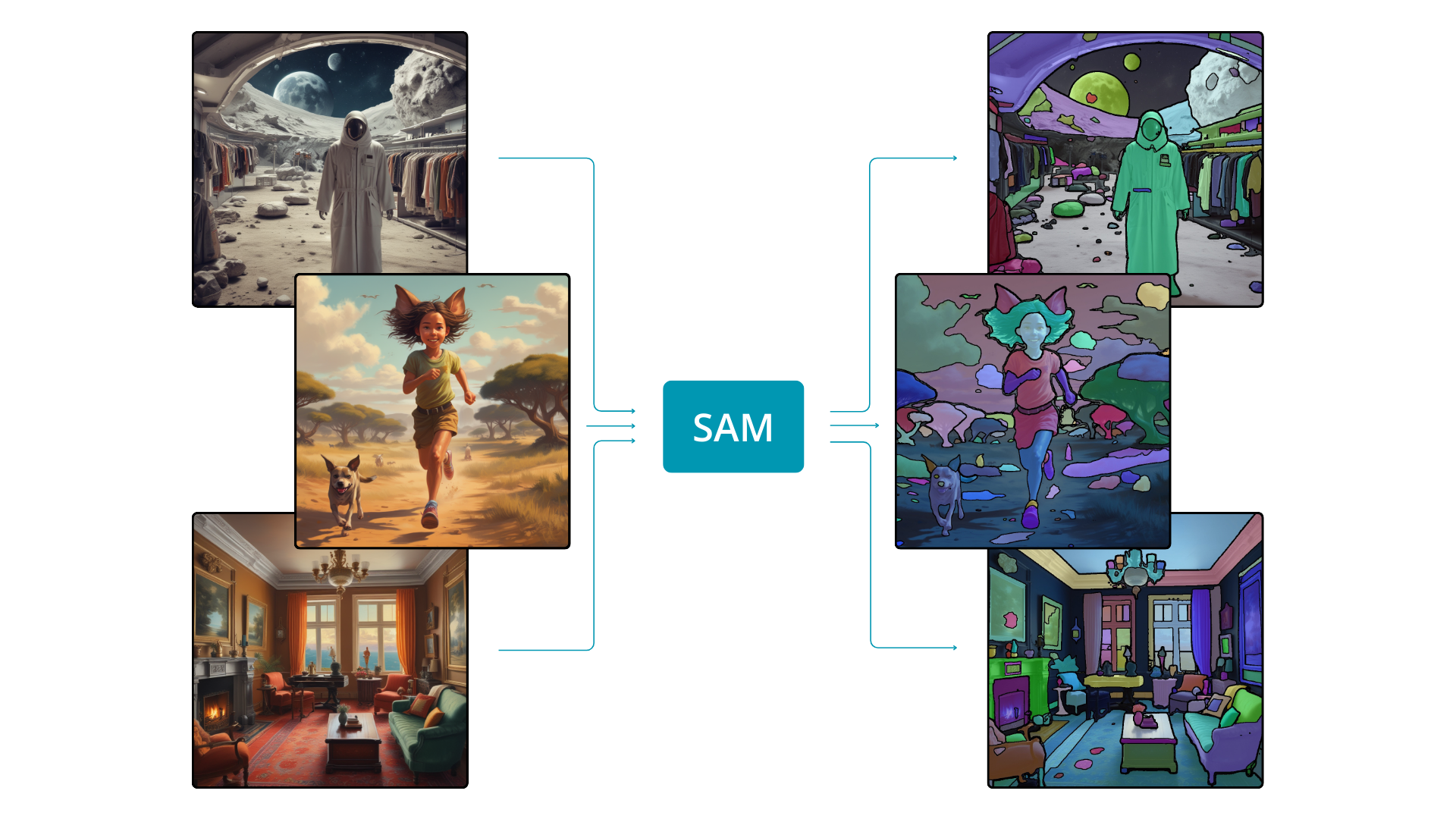
Może jednak uzasadniona byłaby zmiana naszego podejścia. Zamiast uczyć model specyficznego wyglądu samochodu i tego jak wyodrębnić jego maskę z obrazu, możemy poinstruować model w ogólnej umiejętności wyodrębniania dowolnego obiektu z obrazu. To podejście jest podobne do ludzkiej zdolności identyfikowania obiektów na obrazie bez wcześniejszej wiedzy o ich wyglądzie. Jeśli model jest biegły w odróżnianiu pikseli należących do jednego obiektu od pikseli należących do innych obiektów, może rozszerzyć swoją funkcjonalność na obiekty, z którymi nie spotkał się podczas treningu – jest to istota uczenia zero-shot. Model z takimi możliwościami, znany jako Segment Anything Model (SAM), został zaprezentowany już jakiś czas temu i rozpoczął prawdziwą rewolucję w dziedzinie sztucznej inteligencji.
Segment Anything Model jest modelem segmentacji semantycznej działającym na podstawie polecenia (promptu), wyszkolonym do, jak sama nazwa wskazuje, segmentacji czegokolwiek. Aby osiągnąć tą imponującą zdolność do rozróżniania dowolnego obiektu na obrazie, model został wyuczonych przy użyciu ponad jednego miliarda masek segmentacyjnych. SAM ma zdolność do generowania masek dla całego obrazu, a także może zwracać maski na podstawie promptu, którym może być ramka wokół interesującego nas obiektu lub punkt na obrazie.
W celu precyzyjnej segmentacji wybranego obiektu na obrazie, kluczowe jest wykorzystanie ramki ograniczającej. Metoda ta instruuje model, aby skupił swoje wysiłki na segmentacji określonej części obrazu.

Kolejną godną uwagi cechą SAM jest jego zdolność do segmentacji w oparciu o kombinację ramek ograniczających i punktów. Takie zastosowanie jest korzystne w sytuacjach, w których celem jest uzyskanie maski dla określonego obiektu bez uwzględniania innych obiektów w tym samym regionie.

Segmentacja oparta na poleceniu tekstowym
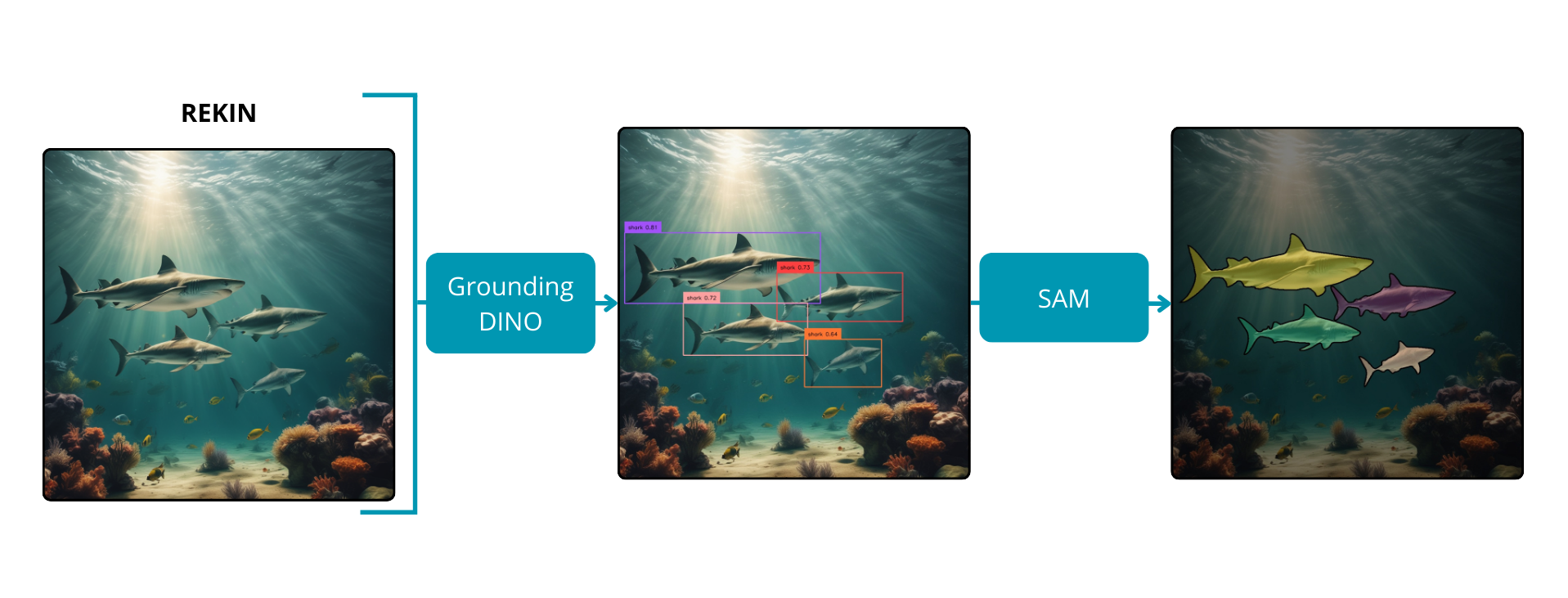
Model Segment Anything osiąga imponujące wyniki; napotyka jednak pewne ograniczenie: brak kontroli użytkownika i szczegółowych informacji o segmentowanych obiektach. Chociaż możliwa jest manipulacja za pomocą ramek ograniczających, wymaga to ręcznego zaznaczania pożądanych obiektów. Na szczęście opracowano rozwiązanie odpowiadające na to ograniczenie – Grounded Segment Anything. Ta innowacja stanowi synergię między modelem Grounding DINO a Segment Anything.
Grounding DINO, model do detekcji obiektów wykazujący zdolności zero-shot, łączy DINO, model do detekcji obiektów oparty na transformatorach, z GLIP, algorytmem, który łączy detekcję obiektów z frazami tekstowymi do szkolenia wstępnego. Integracja ta zwiększa możliwości zer-shot modelu poprzez interpretację danych tekstowych i łączenie ich z odpowiednimi reprezentacjami wizualnymi. Mimo że, Grounding DINO osiąga świetne rezultaty w detekcji obiektów, jego szybkość przetwarzania jest na razie zbyt wolna dla aplikacji działających w czasie rzeczywistym. Niemniej jednak, jego użyteczność w zautomatyzowanych zadaniach adnotacji pozostaje nieoceniona.
Dzięki integracji Grounding DINO z SAM możliwe staje się tworzenie masek dla obrazów wejściowych na podstawie dowolnego tekstu dostarczonego przez użytkownika. Model do detekcji, kierowany danymi tekstowymi, dokładnie przewiduje ramki dla wybranych obiektów. Następnie model segmentacyjny wykorzystuje te współrzędne do generowania masek. To zintegrowane podejście wykorzystuje zarówno mocne strony wykrywania obiektów, jak i segmentacji semantycznej, oferując zwiększoną kontrolę i możliwość interpretacji procesu segmentacji.
Zastosowania
Grounded Segment Anything otwiera drzwi do różnych rozszerzeń, od automatycznej anotacji i kontrolowanej edycji obrazów po opartą na poleceniach tekstowych analizę ruchu człowieka. Ten wszechstronny model może płynnie integrować się z różnymi modelami i algorytmami głębokiego uczenia, aby uzyskać pożądane funkcje. Pojawiło się już wiele interesujących rozszerzeń i bez wątpienia w przyszłości pojawią się kolejne.
- RAM Grounded SAM
Recognize Anything Model (RAM) wyróżnia się jak model głębokiego uczenia do etykietowania obrazów wyposażony w potężne możliwości zero-shot. Ma zdolność do generowania etykiet dla obrazów wejściowych bez potrzeby stosowania ramek ograniczających czy masek. Po zintegrowaniu z Grounded SAM, synergia ta skutkuje kompleksowym narzędziem do automatycznego anotowania obrazów do zadań segmentacyjnych.
W pierwszym etapie, RAM skutecznie zwraca etykiety dla obrazu wejściowego. Etykiety te służą następnie za dane wejściowe dla modelu Grounding DINO. Wreszcie, wraz z dodaniem SAM, proces kończy się wygenerowaniem masek odpowiadających zidentyfikowanym etykietom. Co ciekawe, cały ten cykl odbywa się bez jakiejkolwiek ręcznej interwencji człowieka, oferując znaczną redukcję czasu i kosztów związanych z oznaczaniem obrazów.
Połączenie pracy RAM i Grounded SAM nie tylko usprawnia proces anotacji obrazu, ale także może przyspieszyć rozwój nowych algorytmów sztucznej inteligencji. Poprzez automatyzację procesu anotacji, to zintegrowane podejście zwiększa wydajność i ułatwia płynne połączenie zaawansowanych technik uczenia maszynowego, przyczyniając się tym samym do ewolucji szerokiego zakresu sztucznej inteligencji.

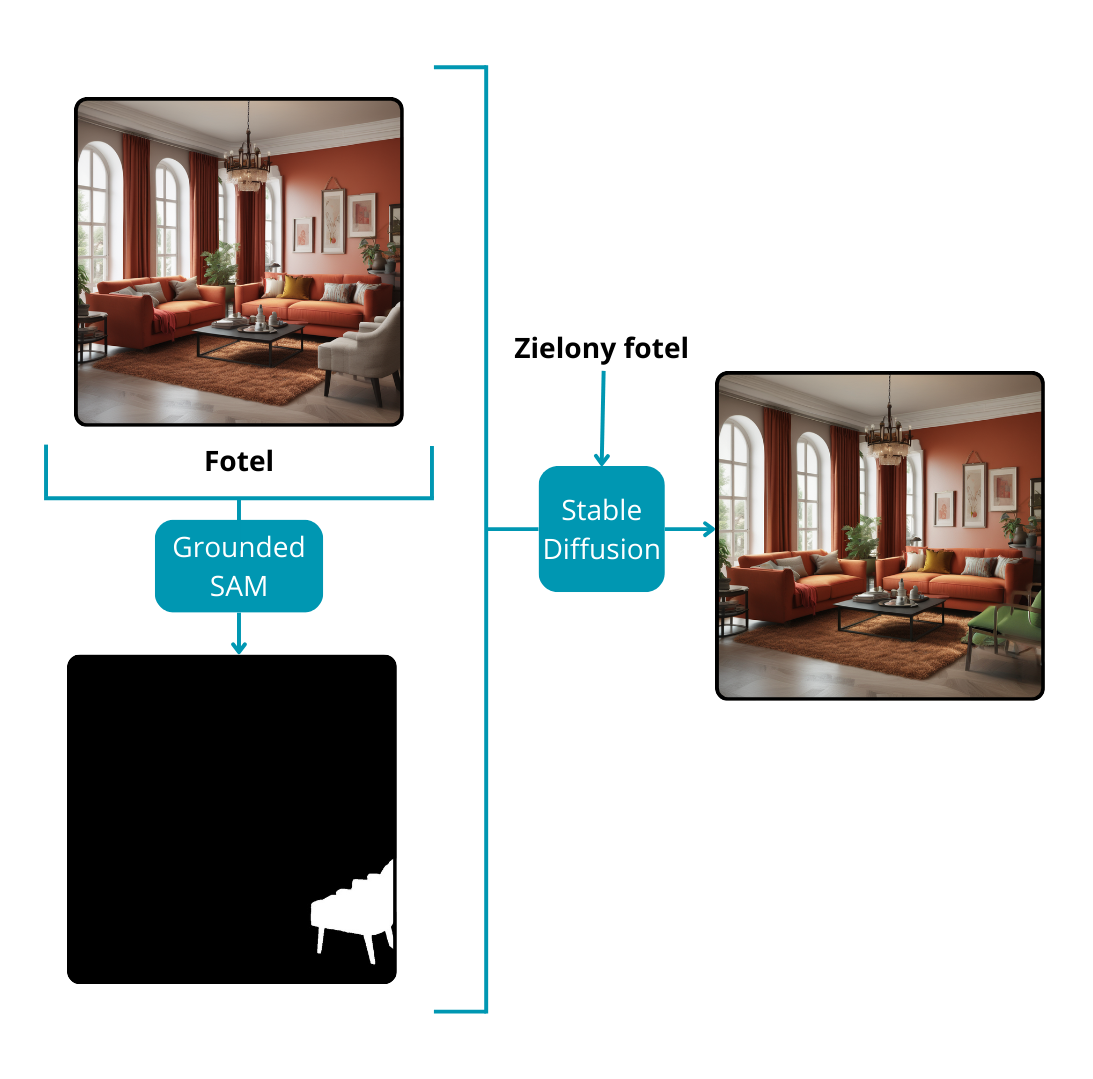
- Grounded SAM i model Stable Diffusion
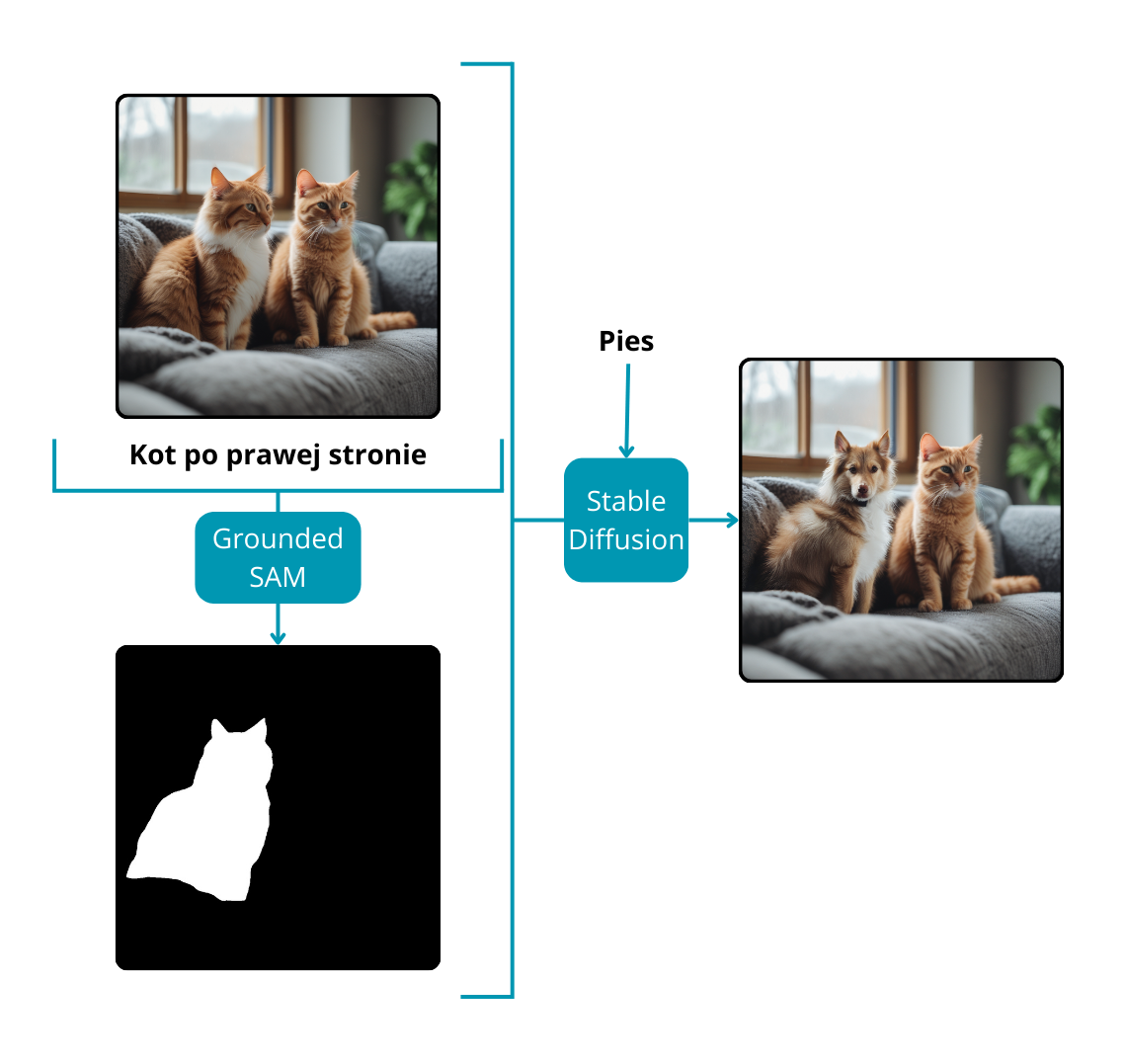
Modele Stable Diffusion specjalizują się w generowaniu obrazów na podstawie poleceń tekstowych lub kombinacji tekstu i obrazu w celu stworzenia zupełnie nowych kompozycji. Poza możliwościami twórczymi, modele te okazują się być cennymi narzędziami do edycji obrazu, zwłaszcza w modyfikowaniu określonych regionów istniejącego obrazu. Aby pokierować modelem podczas zmiany wybranych części obrazu, wymagany jest kluczowy element: maska. Prowadzi to do kompleksowej edycji obrazu bez ręcznej interwencji.
Proces rozpoczyna się od Grounded SAM, który na podstawie monitu tekstowego zwraca maski dla godnych uwagi instancji na obrazie. Następnie użytkownik, uzbrojony w kolejny monit tekstowy, instruuje model Stable Diffusion o pożądanych modyfikacjach dla części obrazu oznaczonych maskami. Dzięki tej iteracyjnej interakcji ostateczny obraz jest płynnie przekształcany. Podejście to jest szczególnie korzystne w przypadku zadań malowania lub wprowadzania zmian między obiektami na obrazie, stanowiąc wszechstronne i wydajne rozwiązanie dla zaawansowanych aplikacji do edycji obrazu.
Aby lepiej zrozumieć modele dyfuzyjne i ich szersze implikacje w dziedzinie sztucznej inteligencji, warto zapoznać się z naszym szczegółowym artykułem tutaj: Czytaj Więcej
Podsumowanie
Pomimo swojego potencjału, uczenie zero-shot w segmentacji napotyka wyzwania, w tym radzenie sobie z drobnymi szczegółami w nieznanych klasach i zapewnienie odporności na zmiany semantyczne. Dodatkowo, czas wnioskowania pozostaje problemem, ponieważ obecne modele segmentacji zero-shot są zbyt wolne dla aplikacji działających w czasie rzeczywistym. Ponieważ badacze nadal pracują nad tymi wyzwaniami, przyszłość niesie ze sobą ekscytujące możliwości udoskonalania i rozszerzania możliwości uczenia zero-shot w segmentacji obrazu.
Płynna segmentacja obrazów: Niestandardowe Rozwiązania Uczenia Zero-Shot od theBlue.ai
W theBlue.ai specjalizujemy się w niestandardowych rozwiązaniach SI dostosowanych do unikalnych potrzeb naszych klientów. Poruszając się po złożoności uczenia zero-shot w segmentacji obrazu, pokonujemy wyzwania, takie jak obsługa drobnych szczegółów, odporność semantyczna i szybkość aplikacji w czasie rzeczywistym. Współpracuj z nami, aby przekształcić te zaawansowane technologie w praktyczne rozwiązania dla Twojej firmy, napędzając innowacje i wydajność. Odkryj różnicę dzięki theBlue.ai.


