Ukryta Moc Wektorowych Baz Danych: Odkrywanie danych i transformacja wyszukiwania w erze generatywnej sztucznej inteligencji

Krzysztof Udycz
AI Engineer
31. May 2023
Sztuczna Inteligencja (SI, ang. Artificial Intelligence, AI), napędzana najnowszymi osiągnięciami w dziedzinie generatywnego AI, przekształca świat, rewolucjonizując sposób, w jaki żyjemy, pracujemy i komunikujemy się. Od chatbotów i autonomicznych samochodów po algorytmy mediów społecznościowych i aplikacje tworzące nowe treści (w tym dźwięk, obrazy i tekst) – sztuczna inteligencja stała się integralną częścią naszego życia. Dzięki zdolności do analizowania ogromnych ilości danych, rozpoznawania wzorców i przewidywania z niezwykłą dokładnością, otworzyły się przed nią nieskończone możliwości w różnych sektorach, w tym w opiece zdrowotnej, finansach, transporcie, edukacji czy rozrywce.
Sztuczna inteligencja przekształca każdą branżę – ale czyniąc to nieumyślnie ujawnia kolejne problemy/wyzwania, których rozwiązanie wymaga nowoczesnych rozwiązań. Tradycyjne bazy danych i metody wyszukiwania dobrze służyły nam przez lata, ale ponieważ złożoność i ilość danych nadal rośnie wykładniczo, napotykają one pewne ograniczenia – potrzeba wydajnego przechowywania, wyszukiwania i przetwarzania złożonych typów danych (głównie nieustrukturyzowanych!) stała się ważniejsza niż kiedykolwiek. Ponadto, jeśli chodzi o generatywną sztuczną inteligencję, kontekst danych odgrywa niezwykle ważną rolę – tradycyjne bazy danych i algorytmy wyszukiwania mają trudności z uwzględnieniem skomplikowanych relacji w złożonych zbiorach danych. Na przykład w handlu elektronicznym zrozumienie preferencji klientów na podstawie ich historii przeglądania, zachowań zakupowych i interakcji społecznych wymaga kompleksowego podejścia, które wykracza poza proste dopasowywanie słów kluczowych.
Kolejnym wyzwaniem dla sztucznej inteligencji jest potrzeba aktualizacji istniejących modeli w celu dokonywania dokładnych, a zarazem aktualnych prognoz – obecne modele są szkolone na danych, które stają się nieaktualne z biegiem czasu. Na przykład ChatGPT – oparty na jednym z najbardziej zaawansowanych obecnie dużych modeli językowych (ang. Large Language Models, LLMs) – został przeszkolony na danych obejmujących okres do końca 2021 roku, a zatem posiada ograniczoną wiedzę na temat bieżących wydarzeń. Na szczęście istnieje rozwiązanie: możemy dostarczyć dodatkowe/własne informacje do modelu (“Bring Your Own Data“), aby uzyskać odpowiedzi na konkretne pytania. Ale jak określić, jakie dane dostarczyć, gdy zbiór danych jest ogromny?
W tym miejscu pojawiają się wektorowe bazy danych (znane również jako wyszukiwarki wektorowe (ang. vector search engines)). Są to wyspecjalizowane systemy przechowywania danych, zaprojektowane w celu efektywnego obsługiwania i przetwarzania wielowymiarowych i bogatych w kontekst danych. W realiach sztucznej inteligencji i uczenia maszynowego mówimy o embedingach – numerycznych reprezentacjach słów, fraz, dokumentów, obrazów lub dowolnego innego typu danych, które przechwytują ich semantyczne znaczenie, a tym samym pozwalają nam określić relacje pomiędzy różnymi embedingami. Embedingi przechowywane są jako wysokowymiarowe i gęste wektory, które niosą ze sobą informacje kluczowe dla sztucznej inteligencji w celu utrzymywania pamięci długoterminowej, a także w pozyskiwaniu i zrozumieniu podstawowych struktur, wzorców i relacji. Embedingi mogą być generowane przez modele AI – BERT, Word2Vec, GloVe lub GPT dla danych tekstowych; konwolucyjne sieci neuronowe (ang. Convolutional Neural Networks, CNNs) dla obrazów; na podstawie spektogramu dźwięku (czyli na podstawie graficznej reprezentacji) – dla audio.
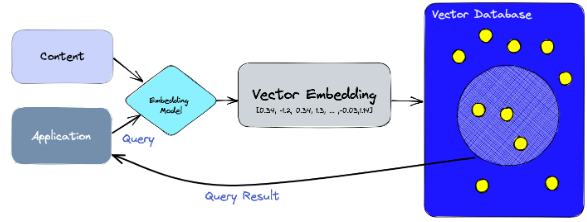
Wektorowe bazy danych oferują dodatkowe korzyści w porównaniu z tradycyjnymi bazami danych, co czyni je lepszym wyborem dla niektórych zastosowań. Oto kilka powodów, dla których wektorowe bazy danych są uważane za lepsze:
- Wsparcie dla różnych typów danych – różne typy danych (tekst, obrazy, dźwięk, wideo itp.) mogą być reprezentowane za pomocą embedingów, co dzięki ujednoliconej reprezentacji pozwala na analizę zróżnicowanych danych w formie wektorowej;
- Wyższa wydajność – wektorowe bazy danych są zoptymalizowane pod kątem obsługi danych wielowymiarowych, umożliwiając szybsze przetwarzanie zapytań. Mogą efektywnie wykonywać złożone operacje matematyczne, takie jak porównania wektorowe, agregacje i wyszukiwania, prześcigając w tych zadaniach tradycyjne bazy danych;
- Efektywne przechowywanie – wektorowe bazy danych wykorzystują techniki kompresji wektorów, dzięki czemu mogą wydajnie przechowywać i przetwarzać wielowymiarowe dane, minimalizując wymagania dotyczące przestrzeni dyskowej i maksymalizując wydajność zapytań;
- Wyszukiwanie kontekstowe i semantyczne – wektorowe bazy danych przechowują znaczenie semantyczne danych i pozwalają na identyfikacje relacji między embedingami, umożliwiając zastosowanie zaawansowanych metod wyszukiwania. Dzięki temu dobrze nadają się do zadań, w których kluczowe znaczenie ma zrozumienie kontekstu i relacji między danymi;
- Wsparcie dla różnych metryk podobieństwa – różne aplikacje czy typy danych wymagają użycia różnych metryk podobieństwa dla algorytmów przybliżonego wyszukiwania najbliższego sąsiada (ang. approximate nearest neighbor search, ANN). Pozwala to na wybranie najbardziej odpowiedniej metryki dostosowanej do konkretnych wymagań użytkownika czy charakteru danych;
- Skalowalność i przetwarzanie rozproszone – skalowalność zapewnia, że modele AI mogą przetwarzać ogromne ilości danych w czasie rzeczywistym, nawet gdy baza danych zwiększa swój rozmiar;
- Przechowywanie i filtrowanie metadanych – wektorowe bazy danych mogą indeksować dodatkowe informacje powiązane z określonym wektorem, umożliwiając dodatkowy poziom filtrowania;
- Aktualizacje w czasie rzeczywistym – możliwość aktualizacji wektorowych bazy danych w czasie rzeczywistym sprawiają, że modele AI mają dostęp do najbardziej aktualnych informacji. Jest to szczególnie przydatne w aplikacjach takich jak chatboty, wirtualni asystenci czy systemy rekomendacji, które wymagają aktualnych danych w celu wygenerowania poprawnych odpowiedzi;
- Integracja z frameworkami AI – wektorowe bazy danych często umożliwiają integracje z popularnymi frameworkami AI, tym samym upraszczając powiązanie danych wektorowych z modelami AI. Taka integracja ułatwia zarządzanie danymi, skracając czas i wysiłek związany z opracowywaniem danych.
Jedną z głównych zalet wektorowych baz danych są ich zaawansowane możliwości wyszukiwania. W przeciwieństwie do tradycyjnych baz danych, które opierają się na częstotliwości lub dokładnych dopasowaniach słów kluczowych, wektorowe bazy danych wykorzystują zróżnicowane miary podobieństwa dla różnych algorytmów przybliżonego wyszukiwania najbliższego sąsiada (ang. approximate nearest neighbor, ANN), aby poznać i określić znaczenie czy relacje pomiędzy danymi. Oznacza to, że mogą znaleźć podobne elementy lub dostarczyć odpowiednie sugestie w oparciu o kontekst zapytania, znajdując najbliższych sąsiadów danego (wektorowego) zapytania. Dzięki temu wyszukiwanie jest dokładniejsze i pomaga odkryć istotne informacje, nawet jeśli nie ma dokładnych dopasowań słów kluczowych. Ogólnie rzecz biorąc, wektorowe bazy danych sprawiają, że wyszukiwanie jest inteligentniejsze, bardziej wydajne, a co najważniejsze, świadome kontekstu, co prowadzi do lepiej dopasowanych wyników i bardziej satysfakcjonującego doświadczenia dla użytkownika.
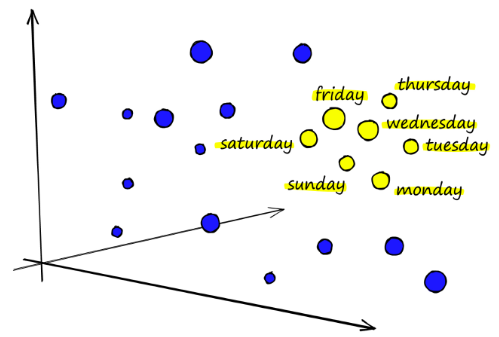
Korzystanie z wyszukiwarek wektorowych nie tylko pozwala na wykorzystanie zaawansowanych możliwości wyszukiwania, ale także stwarza szanse dla rozwoju nowych aplikacji. Oto kilka przykładów tego, co można zbudować przy użyciu wyszukiwarek wektorowych i embedingów:
- Systemy rekomendacyjne – przechowywanie preferencji użytkowników jako wektorów, a następnie wyszukiwanie podobnych elementów lub użytkowników w przestrzeni wektorowej. Rekomendacje są często wykorzystywane w e-commerce lub na platformach streamingowych (takich jak Amazon, eBay, Netflix, YouTube czy Spotify);
- Wyszukiwanie podobieństw/semantyczne (ang. similarity/semantic search) – ponieważ znaczenie i kontekst danych są uchwycone w embedingach, wyszukiwanie wektorowe znajduje to, czego użytkownicy nie potrafią znaleźć bez konieczności dokładnego dopasowania słów kluczowych. Działa to zarówno z danymi tekstowymi (np. Google Search, Yahoo), obrazami (np. Google Reverse Image Search) oraz dźwiękiem (np. Shazam);
- Systemy odpowiadające na pytania (ang. question answering systems) – przedstawienie bazy wiedzy dokumentów i bieżących pytań jako wektorów, a następnie odnajdywanie najbardziej odpowiednich dopasowań na podstawie podobieństwa wektorowego. Jest to przydatne w chatbotach, asystentach wirtualnych czy automatycznych aplikacjach do obsługi klienta;
- Wykrywanie oszustw i anomalii (ang. fraud detection/outlier detection) – modelowanie wzorców zachowań użytkowników jako wektorów i identyfikowanie anomalii lub podejrzanych działań na podstawie metryk podobieństwa. Pomaga to w wykrywaniu podejrzanych transakcji lub działań;
- Personalizowane wyszukiwanie/profilowanie użytkownika – określenie indywidualnych preferencji użytkownika i przechowywanie ich jako wektory. Pozwala to na uzyskanie bardziej relewantnych wyników wyszukiwania, a tym samym poprawę satysfakcji użytkownika;
- Analityka danych (ang. data analytics) – wektorowe bazy danych pozwalają na przeprowadzenie zaawansowanych zadań analitycznych, w tym na grupowanie i klasyfikację, rozpoznawanie wzorców, analizę sentymentu, wykrywanie podobieństwa dokumentów i wiele innych;
- Analiza szeregów czasowych (ang. time series analysis) – bazy danych wektorowych mogą efektywnie przechowywać i analizować dane szeregów czasowych, takie jak odczyty z czujników czy dane finansowe. Przedstawiając szeregi czasowe jako wektory, staje się możliwe przeprowadzanie wyszukiwań opartych na podobieństwie, wykrywanie anomalii oraz identyfikowanie wzorców i trendów w czasie;
- Analiza mediów społecznościowych – analiza relacji i połączeń między osobami. Jest to przydatne do identyfikowania społeczności, influencerów oraz wykrywania wzorców w sieciach społecznościowych;
- Inne – obejmuje przetwarzanie/przeglądanie danych nieustrukturowanych, ponowne sortowanie wyników wyszukiwania, uczenie jednostrzałowe/zerostrzałowe (ang. one-shot/zero-shot learning), wykrywanie błędów/literówek (ang. fuzzy matching), wykrywanie dryftu modelu uczenia maszynowego (ang. model drift), diagnozowanie medyczne, itp.
Dzięki zdolności do obsługi wielowymiarowych danych i wspieraniu zaawansowanych operacji wyszukiwania danych opartych na podobieństwie, wektorowe bazy danych dostarczają wartościowych rozwiązań w wielu dziedzinach i branżach.
Wybór odpowiedniej wektorowej bazy danych zależy od różnych czynników, w tym od rozmiaru, złożoności i ziarnistości danych, a także innych specyficznych wymagań, takich jak koszty, istniejące operacje uczenia maszynowego (MLOps), hosting, wydajność i łatwość konfiguracji. Wszystkie bazy danych oferują efektywny sposób przechowywania i przetwarzania dużych ilości danych, ale ich podejścia mogą się różnić. Każda baza danych może mieć własną unikalną metodologię i techniki obsługi danych wektorowych. Ważne jest, aby zbadać i zrozumieć różnorodne podejścia stosowane przez różne wektorowe bazy danych, aby określić, która z nich najlepiej pasuje do konkretnych potrzeb i preferencji projektu.
Oto kilka najpopularniejszych baz danych wektorowych:
- Weaviate (Managed / Self-hosted vector database / Open source) – wektorowa baza danych, która przechowuje zarówno obiekty, jak i wektory. Pozwala to na połączenie wyszukiwania i filtrowania wektorów. Weaviate może być używana samodzielnie (aka dostarcz swoje własne wektory) lub z różnymi modułami, które mogą samodzielnie wykonać wektoryzację;
- Milvus (Self-hosted vector database / Open source) – wektorowa baza danych stworzona do skalowalnego wyszukiwania podobieństw. Bogata w funkcje, wysoce skalowalna i niesamowicie szybka. Dzięki wektorowej bazie danych Milvus można stworzyć usługę wyszukiwania podobieństw na dużą skalę w mniej niż minutę;
- Pinecone (Managed vector database / Close source) – wektorowa baza danych, która ułatwia łączenie danych firmowych z generatywnymi modelami sztucznej inteligencji w celu uzyskania szybkich, dokładnych i niezawodnych aplikacji bez konieczności zarządzania złożoną infrastrukturą. Jest przyjazna dla programistów, w pełni zarządzana i łatwa do skalowania. Niestety, Pinecone nie ma wbudowanej integracji z zewnętrznymi modelami do generowania embedingów;
- Vespa (Managed / Self-hosted vector database) – kompleksowy silnik wyszukiwania i baza danych wektorowych. Obsługuje wyszukiwanie wektorowe (ANN), wyszukiwanie leksykalne i wyszukiwanie w danych strukturalnych, wszystko w jednym zapytaniu. Zintegrowany model uczenia maszynowego umożliwia zastosowanie AI do analizy danych w czasie rzeczywistym;
- Qdrant (Open Source) – silnik wyszukiwania podobieństwa wektorowego i baza danych wektorowych. Zapewnia gotową do użycia usługę z wygodnym interfejsem API do przechowywania, wyszukiwania i zarządzania wektorami z dodatkowymi danymi. Qdrant jest dostosowany do rozszerzonej obsługi filtrowania, co czyni go przydatnym do wszelkiego rodzaju dopasowania opartego na sieciach neuronowych lub semantyce, wyszukiwania fasetowego i innych zastosowań;
- Chroma (Open Source) – to baza danych embedingów typu open source. Chroma ułatwia tworzenie aplikacji z dużymi modelami językowymi (LLMs), umożliwiając przekazywanie wiedzy, faktów i umiejętności dla large language models;
- Vald – Wykorzystuje najszybszy algorytm ANN NGT do wyszukiwania najbliższych sąsiadów. Vald posiada automatyczną indeksację wektorów oraz kopie zapasowe indeksu, a także skalowanie poziome, które zostało stworzone do wyszukiwania w miliardach wektorów danych. Vald jest łatwy w użyciu, bogaty w funkcje i wysoce konfigurowalny;
- Faiss (Facebook AI Similarity Search) – biblioteka umożliwiająca wydajne wyszukiwanie podobieństwa i grupowanie gęstych wektorów. Zawiera algorytmy przeszukiwania w zbiorach wektorów dowolnego rozmiaru, nawet tych, które nie mieszczą się w pamięci RAM;
- Elastisearch – otwarty silnik do pełnotekstowego wyszukiwania. W wersji 8.0, Elasticsearch dodał wsparcie dla wyszukiwania podobieństwa opartego na wektorach. Elasticsearch obsługuje modele embedingów firm trzecich (m.in. modele Hugging Face)
Ponieważ złożoność i ilość danych nadal rośnie wykładniczo, tradycyjne metody przechowywania i wyszukiwania danych nie są już wystarczające dla pewnych zastosowań. Wektorowe bazy danych stanowią potężną alternatywę dla tradycyjnych metod, umożliwiając odkrywanie cennych, kontekstowych wzorców i relacji w złożonych zbiorach danych. Wykorzystując moc embedingów i wyszukiwania opartego na podobieństwie, organizacje i firmy mogą uwolnić pełny potencjał swoich zasobów danych. Niezależnie od tego, czy chodzi o systemy rekomendacji, wyszukiwanie semantyczne czy wykrywanie oszustw, wektorowe bazy danych i wyszukiwanie wektorowe stały się niezbędnymi narzędziami dla nowoczesnych przedsiębiorstw wykorzystujących ogromne ilości danych. Wykorzystanie potencjału sztucznej inteligencji i uczenia maszynowego będzie miało kluczowe znaczenie dla utrzymania przewagi konkurencyjnej w świecie skoncentrowanym na danych.
Chciałbyś budować aplikacje świadome kontekstu przy użyciu wyszukiwarek wektorowych, ale nie wiesz, od czego zacząć? Skontaktuj się z nami!


