Vektordatenbanken: Revolutionäre Datensuche im Zeitalter von Generativer KI

Krzysztof Udycz
AI Engineer
16. May 2023
Die neue Welle der Künstlichen Intelligenz (KI), vorangetrieben durch die neuesten Fortschritte im Bereich der Generativen KI, verwandelt unsere Welt in rasantem Tempo und revolutioniert die Art und Weise, wie wir leben, arbeiten und interagieren. Von Chatbots und selbstfahrenden Autos über Social-Media-Algorithmen bis hin zu Anwendungen, die neuen Inhalt generieren, einschließlich Audio, Bildern und Texten – Künstliche Intelligenz ist zu einem integralen Bestandteil unseres Lebens geworden. Mit der Fähigkeit, riesige Datenmengen zu analysieren, Muster zu erkennen und äußerst präzise Vorhersagen zu treffen, haben sich unendliche Möglichkeiten in verschiedenen Bereichen eröffnet, darunter Gesundheitswesen, Finanzen, Transport, Bildung und Unterhaltung.
Künstliche Intelligenz transformiert jede Branche – bringt aber auch weitere Herausforderungen mit sich, die moderne Lösungen erfordern. Über die Jahre haben uns herkömmliche Datenbanken und Suchmethoden gut gedient, aber mit dem exponentiellen Wachstum an Komplexität und Datenmenge stoßen sie an ihre Grenzen. Die effiziente Speicherung, Abfrage und Verarbeitung komplexer Daten (insbesondere unstrukturierter Daten!) ist wichtiger denn je geworden. Bei Generative KI spielt auch der Kontext der Daten eine äußerst wichtige Rolle – herkömmliche Datenbanken und Suchalgorithmen haben Schwierigkeiten, komplexe Beziehungen in komplexen Datensätzen zu erfassen. Zum Beispiel erfordert die Analyse der Präferenzen von Kunden im E-Commerce basierend auf ihrem Surfverhalten, ihrem Kaufverhalten und ihren sozialen Interaktionen einen anspruchsvollen Ansatz, der über einfaches Schlüsselwort-Matching hinausgeht.
Eine weitere Herausforderung besteht darin, dass KI-Modelle auf dem neuesten Stand sein müssen, um genaue Vorhersagen zu treffen – aktuelle Modelle werden mit Daten trainiert, die im Laufe der Zeit veraltet werden. Zum Beispiel verwendet ChatGPT eines der fortschrittlichsten Large Language Models von heute, das bis Ende 2021 mit Daten trainiert wurde. Daher hat es nur begrenzte Kenntnisse über aktuelle Ereignisse. Zum Glück gibt es eine Lösung: Sie können BYOD (“Bring Your Own Data”) verwenden, um diesen Modellen die spezifischen Informationen zur Beantwortung Ihrer Fragen bereitzustellen. Aber wie findet man heraus, welche Daten bereitgestellt werden sollen, wenn der Datensatz groß ist?
Genau hier kommen Vektordatenbanken (auch bekannt als Vektor-Suchmaschinen) ins Spiel. Sie sind spezialisierte Datenspeichersysteme, die darauf ausgelegt sind, multidimensionale und kontextreiche Daten effizient zu handhaben und zu verarbeiten. Im Zusammenhang mit KI und maschinellem Lernen sprechen wir von Vektoreinbettungen – numerischen Darstellungen von Wörtern, Phrasen, Dokumenten, Bildern oder anderen Datentypen, die ihre semantische Bedeutung und Beziehungen erfassen und in hochdimensionalen und dichten Vektoren gespeichert sind. Einbettungen enthalten Informationen, die für die KI von entscheidender Bedeutung sind, um das Langzeitgedächtnis aufrechtzuerhalten und eine Wahrnehmung und ein Verständnis der zugrunde liegenden Strukturen, Muster und Beziehungen zu erlangen. Sie können von KI-Modellen generiert werden – BERT, Word2Vec, GloVe oder GPT für Textdaten; Faltungsneuronale Netze (CNNs) für Bilder; Bild-Einbettungstransformationen über das Klangspektrogramm – für Audio.
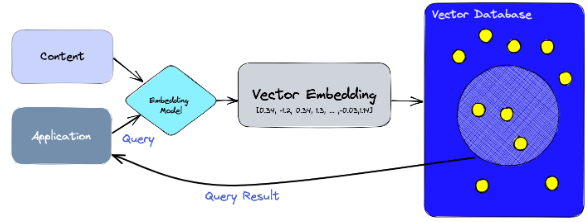
Vektordatenbanken bieten mehrere Vorteile gegenüber herkömmlichen Datenbanken und sind daher für bestimmte Anwendungen die bessere Wahl. Hier sind einige Gründe, warum Vektordatenbanken als besser angesehen werden:
- Unterstützung verschiedener Datentypen: Verschiedene Datentypen (Text, Bilder, Audio, Video usw.) können in Vektoreinbettungen umgewandelt werden, was eine einheitliche Darstellung und Analyse verschiedener Daten in vektorisierter Form ermöglicht.
- Höhere Leistung: Vektordatenbanken sind optimiert, um hochdimensionale Daten zu verarbeiten und ermöglichen eine schnellere Abfrageverarbeitung. Sie können komplexe mathematische Operationen wie Vektorvergleiche, Aggregationen und Suchvorgänge effizient durchführen und dabei herkömmliche Datenbanken übertreffen.
- Effiziente Speicherung: Vektordatenbanken verwenden Vektor-Kompressionstechniken, um hochdimensionale Vektorrepräsentationen effizient zu speichern und abzurufen, wodurch der Speicherbedarf minimiert und die Abfrageleistung maximiert wird.
- Kontextuelle und semantische Suche: Vektordatenbanken erfassen die semantische Bedeutung und kontextuellen Beziehungen zwischen Einbettungen und ermöglichen fortschrittliche Suchfunktionen. Dadurch eignen sie sich besonders gut für Anwendungen, bei denen das Verständnis des Kontexts und der Beziehungen zwischen Daten entscheidend ist.
- Unterstützung verschiedener Ähnlichkeitsmetriken: Unterschiedliche Ähnlichkeitsmetriken für approximative “nächster-Nachbar”-Algorithmen können unterschiedlichen Anwendungsfällen und Datentypen gerecht werden, wodurch Benutzer die geeignetste Metrik basierend auf ihren spezifischen Anforderungen und der Art ihrer Daten auswählen können.
- Skalierbarkeit und verteilte Verarbeitung: Skalierbarkeit stellt sicher, dass KI-Modelle auch bei wachsenden Datenbanken in Echtzeit große Datenmengen verarbeiten können.
- Metadatenspeicherung und -filterung: Vektordatenbanken können zusätzliche Informationen, die mit jedem Vektoreintrag verknüpft sind, indizieren, was eine zusätzliche Ebene der Filterung ermöglicht.
- Echtzeitaktualisierungen: Durch die Möglichkeit der Echtzeitaktualisierung stellen Vektordatenbanken sicher, dass KI-Modelle Zugriff auf die aktuellsten Informationen haben. Diese Funktion ist besonders nützlich für Anwendungen wie Chatbots, virtuelle Assistenten und Empfehlungssysteme, die aktuelle Daten für genaue Antworten benötigen.
- Integration mit KI-Frameworks: Vektordatenbanken bieten häufig Bibliotheken und Integrationen mit beliebten KI-Frameworks, was die Integration von Vektordaten in KI-Modelle vereinfacht. Diese Integrationen erleichtern die Datenpflege, reduzieren die Entwicklungszeit und den Aufwand.
Mit der Fähigkeit, hochdimensionale Daten zu verarbeiten und fortgeschrittene Operationen zu unterstützen, bieten Vektordatenbanken wertvolle Lösungen in einer Vielzahl von Bereichen und Branchen.
Die Auswahl der geeigneten Vektordatenbank hängt von verschiedenen Faktoren ab, darunter die Größe, Komplexität und Granularität der Daten sowie andere spezifische Anforderungen wie Kosten, bestehende Machine Learning Operations (MLOps), Hosting, Leistung und einfache Konfiguration. Alle Datenbanken bieten eine effiziente Möglichkeit, große Datenmengen zu speichern und zu verarbeiten, jedoch können ihre Ansätze variieren. Jede Datenbank kann ihre eigene einzigartige Methodik und Techniken zur Handhabung von Vektordaten haben. Es ist wichtig, die verschiedenen Ansätze zu erkunden und zu verstehen, die von verschiedenen Vektordatenbanken verwendet werden, um festzustellen, welche am besten zu den spezifischen Projektanforderungen und -präferenzen passt.
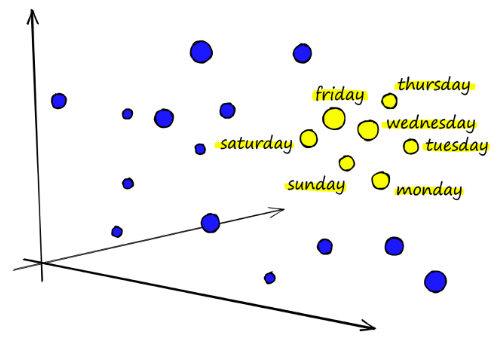
Die Verwendung von Vektorsuchmaschinen ermöglicht nicht nur erweiterte Suchfunktionen, sondern schafft auch Möglichkeiten für neue Anwendungen und Entwicklungen. Hier sind einige Beispiele dafür, was mit Vektorsuchmaschinen und Einbettungen erstellt werden kann:
- Empfehlungssysteme – indem Benutzerpräferenzen als Vektoren gespeichert und anschließend ähnliche Elemente oder Benutzer im Einbettungsraum gefunden werden. Empfehlungen werden häufig im E-Commerce oder von Streaming-Plattformen (wie Amazon, eBay, Netflix, YouTube oder Spotify) eingesetzt.
- Ähnlichkeit/Semantische Suche – da die Bedeutung und der Kontext der Daten in der Einbettung erfasst werden, findet die Vektorsuche heraus, was Benutzer meinen, ohne eine genaue Schlüsselwortübereinstimmung zu erfordern. Sie funktioniert mit Textdaten (z. B. Google-Suche, Yahoo), Bildern (z. B. Google Reverse Image Search) oder Audio (z. B. Shazam).
- Frage-Antwort-Systeme – indem die Wissensbasis von Dokumenten und aktuellen Fragen als Vektoren abgebildet und anhand der Vektorsimilarität die relevanteste Übereinstimmung als Antwort abgerufen wird. Dies ist nützlich bei Chatbots, virtuellen Assistenten und Kundensupport-Anwendungen.
- Betrugserkennung/Ausreißererkennung – durch Modellierung von Benutzerverhaltensmustern als Vektoren und Identifizierung von Anomalien oder verdächtigen Aktivitäten anhand von Ähnlichkeitsmetriken. Dies hilft bei der Erkennung betrügerischer Transaktionen oder Aktivitäten.
- Personalisierte Suche/Benutzerprofilierung – Erfassung von Benutzerpräferenzen und Speicherung als Vektoren. Dies führt zu relevanteren Suchergebnissen und einer verbesserten Benutzerzufriedenheit.
- Datenanalyse – Vektordatenbanken unterstützen fortgeschrittene Aufgaben der Datenanalyse, einschließlich Clusterbildung und Klassifizierung, Mustererkennung, Stimmungsanalyse, Dokumentsimilarität und mehr.
- Zeitreihenanalyse – Vektordatenbanken können zeitliche Daten effizient speichern und analysieren, wie z. B. Sensormesswerte oder Finanzdaten. Durch die Darstellung von Zeitreihen als Vektoren wird es möglich, ähnlichkeitsbasierte Suchen durchzuführen, Anomalien zu erkennen oder Muster und Trends im Laufe der Zeit zu identifizieren.
- Analyse sozialer Medien – Analyse von Beziehungen und Verbindungen von Einzelpersonen. Dies ist hilfreich zur Identifizierung von Gemeinschaften, Influencern und zur Erkennung von Mustern in sozialen Netzwerken.
- Sonstiges – einschließlich der Vorverarbeitung/Durchsuchung von unstrukturierten Daten, erneutes Sortieren von Suchergebnissen, One-Shot/Zero-Shot-Learning, Tippfehlererkennung (unscharfe Übereinstimmung), Erkennung von veralteten maschinellen Lernmodellen (Drift), medizinische Diagnose usw.
Mit der Fähigkeit, hochdimensionale Daten zu verarbeiten und fortschrittliche ähnlichkeitsbasierte Operationen zu unterstützen, bieten Vektordatenbanken wertvolle Lösungen in einer Vielzahl von Bereichen und Branchen.
Die Auswahl der geeigneten Vektordatenbank hängt von verschiedenen Faktoren ab, darunter Größe, Komplexität und Granularität der Daten sowie andere spezifische Anforderungen wie Kosten, vorhandene Machine Learning Operations (MLOps), Hosting, Leistung und einfache Konfiguration. Alle Datenbanken bieten eine effiziente Möglichkeit, große Datenmengen zu speichern und zu verarbeiten, aber ihre Ansätze können variieren. Jede Datenbank kann ihre eigene einzigartige Methodik und Techniken zur Handhabung von Vektordaten haben. Es ist wichtig, die verschiedenen Ansätze zu erkunden und zu verstehen, die von verschiedenen Vektordatenbanken verwendet werden, um festzustellen, welche am besten zu den spezifischen Projektanforderungen und -präferenzen passt.
Hier sind einige der beliebtesten Vektordatenbanken:
- Weaviate (Verwaltete/Selbst gehostete Vektordatenbank/Open Source) – Eine Vektordatenbank, die sowohl Objekte als auch Vektoren speichert. Dies ermöglicht die Kombination von Vektorsuche und Filterung. Weaviate kann eigenständig verwendet werden (d. h. eigene Vektoren mitbringen) oder mit verschiedenen Modulen, die die Vektorisierung für Sie durchführen können.
- Milvus (Selbst gehostete Vektordatenbank/Open Source) – Eine für skalierbare Ähnlichkeitssuche entwickelte Vektordatenbank. Mit umfangreichen Funktionen, hoher Skalierbarkeit und hoher Geschwindigkeit. Mit der Milvus-Vektordatenbank können Sie in weniger als einer Minute einen Ähnlichkeitssuchdienst im großen Maßstab erstellen.
- Pinecone (Verwaltete Vektordatenbank/Proprietär) – Eine Vektordatenbank, die es einfach macht, Ihre Unternehmensdaten mit generativen KI-Modellen für schnelle, genaue und zuverlässige Anwendungen zu verbinden, ohne eine komplexe Infrastruktur verwalten zu müssen. Es ist benutzerfreundlich, vollständig verwaltet und einfach zu skalieren. Leider hat Pinecone keine integrierte Integration mit Einbettungsmodellen.
- Vespa (Verwaltete/Selbst gehostete Vektordatenbank) – Eine voll ausgestattete Suchmaschine und Vektordatenbank. Sie unterstützt die Vektorsuche (ANN), die lexikalische Suche und die Suche in strukturierten Daten in einer einzigen Abfrage. Die integrierte Modellinferenz ermöglicht die Anwendung von KI, um Ihre Daten in Echtzeit zu verstehen.
- Qdrant (Open Source) – Eine Vektorsimilaritätssuchmaschine und Vektordatenbank. Es bietet einen einsatzbereiten Service mit einer praktischen API zum Speichern, Suchen und Verwalten von Punkten – Vektoren mit zusätzlichen Nutzdaten. Qdrant ist auf erweiterte Filterunterstützung zugeschnitten und eignet sich für alle Arten von neuronaler Netzwerk- oder semantikbasierten Abgleichen, facettierter Suche und anderen Anwendungen.
- Chroma (Open Source) – Eine Open-Source-Einbettungsdatenbank. Chroma erleichtert den Aufbau von Apps mit großen Sprachmodellen, indem es Wissen, Fakten und Fähigkeiten für LLMs (Large Language Models) einbindet.
- Vald – Es verwendet den schnellsten ANN-Algorithmus NGT, um Nachbarn zu suchen. Vald verfügt über automatische Vektorindizierung und Index-Backup sowie horizontales Skalieren, das für die Suche in Milliarden von Merkmalsvektor-Daten entwickelt wurde. Vald ist einfach zu bedienen, bietet umfangreiche Funktionen und ist stark anpassbar.
- Faiss (Facebook AI Similarity Search) – Eine Bibliothek für effiziente Ähnlichkeitssuche und Clusterbildung von dichten Vektoren. Sie enthält Algorithmen, die in Vektorsätzen jeder Größe suchen, auch solche, die möglicherweise nicht in den Arbeitsspeicher passen.
- Elasticsearch ist eine Open-Source-Volltextsuchmaschine. In Version 8.0 hat Elasticsearch die Unterstützung für die Ähnlichkeitssuche von Vektoren hinzugefügt. Elasticsearch unterstützt auch Texteinbettungsmodelle von Drittanbietern.
Mit der exponentiellen Zunahme der Komplexität und des Volumens von Daten reichen die herkömmlichen Methoden der Datenspeicherung und -suche nicht mehr aus, um bestimmte Anwendungen zu bewältigen. Vektordatenbanken bieten eine leistungsstarke Alternative zu herkömmlichen Methoden und ermöglichen die Entdeckung wertvoller, kontextbewusster Muster und Beziehungen in komplexen Datensätzen. Indem sie die Kraft von Einbettungen und Abfragen nutzen, können Organisationen das volle Potenzial ihrer Daten ausschöpfen. Ob in Empfehlungssystemen, semantischer Suche oder Betrugsbekämpfung – Vektordatenbanken und Vektorsuche sind unverzichtbare Werkzeuge für moderne datengetriebene Unternehmen geworden. Die Nutzung von künstlicher Intelligenz und maschinellen Lernens wird entscheidend sein, um einen Wettbewerbsvorteil in einer datenzentrierten Welt zu erhalten.
Möchten Sie kontextbewusste Anwendungen mit Vektorsuchmaschinen erstellen, wissen aber nicht, wo Sie anfangen sollen? Wir stehen Ihnen gerne zur Verfügung. Kontaktieren Sie uns noch heute.
