How does a computer know what the text is about?

Roman Kaczorowski
AI Engineer
July 26th, 2018
From fear, confusion, and anxiety to fascination and excitement. Artificial Intelligence raises many emotions.
The topic modeling is used to discover abstract themes that occur in a large amount of unstructured content. It is a kind of unsupervised machine learning that uses grouping techniques to find hidden structures.
Topic modeling in Python using the Gensim library
Natural language processing (NLP) is a field of artificial intelligence that combines machine learning with linguistics. It is used to automatically analyze text to understand content, translate between languages or generate new text. One of the many applications of such processing is to extract key phrases, or even topics, which appeared in a large number of texts.
The topic modeling is used to discover abstract themes that occur in a large amount of unstructured content. It is a kind of unsupervised machine learning that uses grouping techniques to find hidden structures.
The same methods are used by Google News to group messages from different portals into a single set. The words appearing in a given set of texts are transformed into a probabilistic model, thus creating a set of “topics”.
Application of topic modeling
Topic modeling turns out to be very useful in working on extensive collections of text documents, to discover the relationship between them, without first familiarizing oneself with the content. The algorithm allows you to generate keywords, which helps to understand the leitmotif of a given document.
Human reading the large volumes of data and drawing coherent conclusions from them would, in turn, be too time-consuming and complicated. The automation of this process by NLP technologies is helpful.

Awareness of popular topics in discussions and a good understanding of people’s problems and opinions is a valuable asset for many companies, social network administrators, and policy options. It can help in this topic modeling by presenting the relationships between words, which turns out to be useful in the next grouping of these contents.
Some services use this technique to support their recommendation system. Others to improve search results to provide users with the best-fitting documents. Topic modeling is also used to discover trends, i.e., topics that are of great interest.
How does topic modeling work?
Assuming that each document deals with a specific topic, one can surely expect that particular words or phrases will appear more frequently in the document. For example, the names of vegetables and fruits will appear in the healthy nutrition content, and the words ‘engine’ or ‘wheel’ will appear in the automotive document.
The topics created by topic modeling are clusters of similar words. This is a kind of the equivalent of human intuition in the form of a mathematical model. It allows you to examine many documents and discover potential topics and relationships between them. The whole system is based on statistics.
The most popular topic modeling algorithms include Latent Derelicht Analysis (LDA). It is a probabilistic model that uses two probability values: P (word | topics) and P (themes | documents) to create clusters.
The topic modeling algorithm assumes that each document is represented by a division into topics and that each topic is represented by a word decomposition. In addition, the number of topics should be given at the beginning of the processing, even if it is not clear what the topics are.
First data processing
Before working with LDA, you must first process unstructured documents properly. To do so, all punctuation marks have to be removed from the document, and the whole content must be divided into tokens according to the words. Then you must delete all the tokens in the stopwords list. Also, Wordnet NLTK can be used to find synonyms and antonyms.
Moreover, it is worthwhile to subject the texts to a process of lemmatization, which consists in bringing a group of words which are a variant of the same phrase into a uniform form. For instance, in Polish, verbs are converted into infinitive and nouns into singular denominators. Thanks to this process we get the core of the word.
Once the data has been converted, it should be put in the nested list format, “nested list”, such as:
dataset = [
['visit', 'olivio', 'group', 'people', 'order', 'sharing', 'antipasti', 'pasta', 'pizza'],
['special', 'totally', 'limited', 'production', 'number', 'though', 'pista', 'range'],
['choppy', 'prone', 'sloppy', 'wheel', 'control', 'particularly', 'around'],
…
]
LDA using the Gensim library
After processing the text data, a dictionary is created from all the appearing words. Then the body is converted to a bag-of-words form, which reflects the occurrence of words in the document. The full text is transformed into a representation of two things: all occurring words and a measure of the number of specific words in the text. Any information about the words’ order is rejected, causing the model to be able to determine whether a word appears in the document and where not.
from gensim import corpora
id2word = corpora.Dictionary(dataset)
corpus = [id2word.doc2bow(text) for text in dataset]
Using the built-in function in the Gensim library, an LDA algorithm is invoked to find 5 topics in the documents. The found topics are displayed at the end.
um_topics = 5
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=num_topics,
alpha='auto')
topics = lda_model.print_topics(num_words = 3)
for topic in topics:
print(topic)
[
(0, '0.016*"pasta" + 0.015*"great" + 0.008*"carbonarra"'),
(1, '0.020*"secure" +0.020*"healthcare" + 0.015*"solution”'),
(2, '0.021*"pizza" + 0.014*"restaurant " + 0.014*"pasta”'),
(3, '0.019*"volcano" + 0.019*"guatemala" + 0.019*"pacific"'),
(4, '0.029*"wheel" + 0.015*"suspension" + 0.015*" drive”')
]
How should the results be read?
A comma separates each generated topic. Within each topic, there is k of the most probable words that appear in it, where k is a positive natural number given by the user. In this case, 3 keywords each have been assigned to one topic.
The results show that themes 0 and 2 will concern Italian food, 1 will focus on health, 3 will focus on the volcano in Guatemala, and the last is concerning car building.
Topic Coherence
To measure the topic coherence is used to assess the integrity of the model resulting from the LDA algorithm. The higher the value, the better the fit. The valuable result here would be coherent topics so can be described using a short label.
It can be very problematic to determine the optimal number of topics without going into the content. To do this, you need to build many LDA models, with the different number of topics, and choose the one that gives the highest score.
Choosing too much value in the number of topics often leads to more detailed sub-themes, where some keywords repeat.
The code below shows how to find the optimal number of topics for the document collection. At the end of the chart, you can read how the topic coherence value changes for a different number of topics.
import pandas as pd
from tqdm import tqdm
from gensim import models, corpora
from ggplot import *
%matplotlib inline
def lda(corpus,id2word,dataset,topic_num):
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word, num_topics=topic_num,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
coherence_model_lda = CoherenceModel(model=lda_model, texts=dataset, dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
topics = lda_model.print_topics(-1)
return coherence_lda, topics, lda_model
def find_topics(start, end, dataset):
id2word = corpora.Dictionary(dataset)
corpus = [id2word.doc2bow(text) for text in dataset]
coherence_array = []
topics_array = []
topic_range = range(start,end)
lda_model_array = []
for topic_num in tqdm(topic_range):
coherence_lda, topics, lda_model = lda(corpus,id2word,dataset,topic_num)
topics_array.append(topics)
coherence_array.append(coherence_lda)
lda_model_array.append(lda_model)
return {'coherence_array': coherence_array, 'topics_array': topics_array, 'lda_model_array':lda_model_array, 'corpus':corpus, 'id2word':id2word, 'topic_range':topic_range}
results = find_topics(5,50,dataset_temp)
coherence_plot_pd = pd.DataFrame({'y_data': results['coherence_array'], 'x_data': results['topic_range']})
ggplot(aes(x='x_data', y='y_data'), data=coherence_plot_pd) + geom_line()
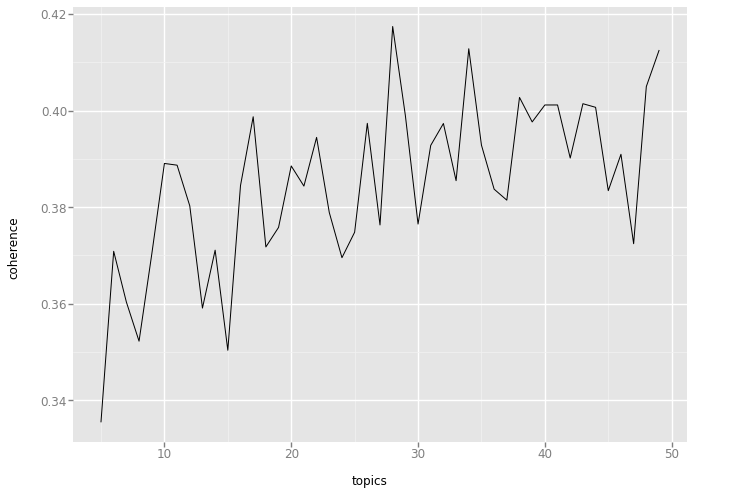
From the chart above, it can be read that the highest value of topic coherence is for the model with 28 topics.
pyLDAvis
pyLDAvis is designed to help users interpret topics found by the algorithm. This is the best way to illustrate the distribution of topics – keywords.
The library extracts information from the resulting LDA model to create interactive visualization:
A good model will include as few overlapping objects as possible, with a relatively large size for each topic.
Conclusions
Latent Dirichlet Allocation is the most popular topic modeling algorithm. It allows detecting topics in unstructured documents. The algorithm is used for text grouping, information searching, and trend detection.
A good way to compare different LDA models based on their interpretability is through topic coherence. The results can be easily visualized using the pyLDAvis library.
")