Skąd komputer wie o czym jest tekst?

Roman Kaczorowski
Inżynier AI
27 czerwca 2018
Topic modeling w Pythonie z użyciem biblioteki Gensim
Do odkrywania abstrakcyjnych tematów występujących w dużej ilości nieustrukturyzowanej treści służy topic modeling. Jest to rodzaj nienadzorowanego uczenia maszynowego, który stosuje techniki grupowania do znajdowania ukrytych struktur.
Natural language processing (NLP) to dziedzina sztucznej inteligencji, która łączy w sobie zagadnienia uczenia maszynowego oraz językoznawstwa. Wykorzystuje się ją do dokonywania automatycznej analizy tekstu w celu zrozumienia treści, tłumaczeń między językami lub generowania nowego tekstu. Jedno z wielu zastosowań takiego przetwarzania jest wyodrębnianie fraz kluczowych, czy nawet tematów jakie pojawiły się w dużej liczbie tekstów.
Do odkrywania abstrakcyjnych tematów występujących w dużej ilości nieustrukturyzowanej treści służy topic modeling. Jest to rodzaj nienadzorowanego uczenia maszynowego, który stosuje techniki grupowania do znajdowania ukrytych struktur.
Te same metody stosowane są przez Google News, aby pogrupować wiadomości z różnych portali w jeden zestaw. Słowa występujące w danym zbiorze tekstów, zamieniane są w model probabilistyczny, tworząc tym samym zbiór „tematów”.
Zastosowanie topic modelingu
Topic modeling okazuje się bardzo przydatny w pracy na dużych zbiorach dokumentów tekstowych, do odkrycia zależności między nimi, bez uprzedniego zapoznania się z treścią. Algorytm umożliwia wygenerowanie słów kluczowych, co pozwala zrozumieć temat przewodni danego dokumentu.
Przeczytanie przez człowieka dużych wolumenów danych i wyciągnięcie z nich spójnych tematów byłoby z kolei zbyt czasochłonne i skomplikowane. Z pomocą przychodzi automatyzacja tego procesu przez technologie NLP.

Świadomość popularnych tematów w dyskusjach i dobre zrozumienie problemów oraz opinii ludzi to cenna wartość dla wielu firm, administratorów serwisów społecznościowych i opcji politycznych. Może pomóc w tym topic modeling prezentując związki pomiędzy słowami, co okazuje się przydatne w późniejszym grupowaniu tych treści.
Niektóre serwisy używają tej techniki jako wsparcia systemu rekomendacyjnego. Inne z kolej do poprawienia wyników wyszukiwania, aby dostarczyć użytkownikom najlepiej dopasowane dokumenty. Topic modeling znajduje również zastosowanie w odkrywaniu trendów, czyli takich tematów które cieszą się dużym zainteresowaniem.
Jak działa topic modeling?
Zakładając, że każdy dokument dotyczy określonego tematu, można śmiało oczekiwać, że konkretne słowa lub wyrażenia będą pojawiać się w nim częściej. Przykładowo, nazwy warzyw oraz owoców będą występować w treści dotyczącej zdrowego odżywiania, a słowa „silnik” czy „koło” pojawią się w dokumencie związanym z motoryzacją.
Tematy tworzone przez topic modeling to klastry podobnych do siebie słów. Stanowi to swego rodzaju odpowiednik ludzkiej intuicji w formie matematycznego modelu. Pozwala on na zbadanie wielu dokumentów i odkrycie potencjalnych tematów i relacji między poszczególnymi dokumentami. Cały system opiera się na statystyce.
Do najbardziej popularnych algorytmów topic modelingu zalicza się Latent Derelicht Analysis (LDA). Jest to model probabilistyczny, który wykorzystuje dwie wartości prawdopodobieństwa: P (słowo | tematy) i P (tematy | dokumenty) do stworzenia klastrów.
Algorytm topic modeling zakłada, że każdy dokument jest reprezentowany przez podział na tematy, oraz że każdy temat jest reprezentowany jako rozkład na słowa. Ponadto, liczbę tematów należy podać na początku przetwarzania, nawet jeśli nie ma pewności, jakie są tematy.
Wstępne przetworzenie danych
Przed rozpoczęciem pracy z LDA, należy najpierw odpowiednio przetworzyć nieustrukturyzowane dokumenty. W tym celu trzeba usunąć z dokumentu wszystkie znaki interpunkcyjne i podzielić całość według słów na tokeny. Następnie należy skasować wszystkie tokeny znajdujące się na liście stopwords. Dodatkowo można użyć Wordnetu NLTK do znalezienia synonimów oraz antonimów.
Ponadto, teksty warto poddać procesowi lematyzacji, który polega na sprowadzeniu grupy wyrazów stanowiących odmianę tego samego sformułowania do jednolitej postaci. Przykładowo, w języku polskim czasowniki zostają zamienione na bezokoliczniki, a rzeczowniki na mianownik liczby pojedynczej. Dzięki temu procesowi otrzymujemy główny trzon słowa.
Po przekonwertowaniu danych powinny mieć one format zagnieżdżonej listy, jak np.:
dataset = [
['visit', 'olivio', 'group', 'people', 'order', 'sharing', 'antipasti', 'pasta', 'pizza'],
['special', 'totally', 'limited', 'production', 'number', 'though', 'pista', 'range'],
['choppy', 'prone', 'sloppy', 'wheel', 'control', 'particularly', 'around'],
…
]
LDA z użyciem biblioteki Gensim
Po przetworzeniu danych tekstowych, tworzony jest słownik ze wszystkich pojawiających się słów. Następnie zachodzi konwersja korpusu do postaci bag-of-words, która odzwierciedla występowanie słów w dokumencie. Pełen tekst zostaje zamieniony do reprezentacji obejmującej dwie rzeczy: wszystkie występujące słowa oraz miarę ilości danych słów w tekście. Wszelkie informacje o kolejności słów są odrzucane, powodując tym samym że model jest w stanie określić czy dane słowo pojawia się w dokumencie, ale nie gdzie występuje.
from gensim import corpora
id2word = corpora.Dictionary(dataset)
corpus = [id2word.doc2bow(text) for text in dataset]
Wykorzystując wbudowaną funkcję w bibliotece Gensim, wywoływany jest algorytm LDA do znalezienia 5 tematów w dokumentach. Na końcu wyświetlane są znalezione tematy.
um_topics = 5
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=num_topics,
alpha='auto')
topics = lda_model.print_topics(num_words = 3)
for topic in topics:
print(topic)
[
(0, '0.016*"pasta" + 0.015*"great" + 0.008*"carbonarra"'),
(1, '0.020*"secure" +0.020*"healthcare" + 0.015*"solution”'),
(2, '0.021*"pizza" + 0.014*"restaurant " + 0.014*"pasta”'),
(3, '0.019*"volcano" + 0.019*"guatemala" + 0.019*"pacific"'),
(4, '0.029*"wheel" + 0.015*"suspension" + 0.015*" drive”')
]
Jak odczytywać wyniki?
Każdy wygenerowany temat jest oddzielony przecinkiem. W ramach każdego tematu jest k najbardziej prawdopodobnych słów, które się w nim pojawiły, gdzie k jest dodatnią liczbą naturalną podaną przez użytkownika. W tym przypadku do jednego tematu zostały przyporządkowane po 3 słowa kluczowe.
Na podstawie otrzymanych wyników można zauważyć, że tematy 0 oraz 2 będą dotyczyć włoskiego jedzenia, 1 temat koncentruje się wokół zdrowia, 3 temat porusza wątek wulkanu w Gwatemali, a ostatni temat odnosi się do budowy samochodu.
Topic Coherence
Do oceny spójności modelu powstałego w wyniku algorytmu LDA wykorzystywana jest miara zwana topic coherence. Im wyższa jest jej wartość, tym uzyskuje się lepsza dopasowanie. Wartościowym rezultatem będą tu tematy spójne, czyli takie które można opisać za pomocą krótkiej etykiety.
Określenie optymalnej liczby tematów bez zagłębiania się w treść może okazać się bardzo problematyczne. Aby to zrobić, należy zbudować wiele modeli LDA, z różną ilością tematów i wybrać ten, który daje najwyższy wynik.
Wybranie zbyt dużej wartości w liczbie tematów często prowadzi do powstania bardziej szczegółowych podtematów, gdzie część słów kluczowych się powtarza.
Poniższy kod prezentuje, jak znaleźć optymalną liczbę tematów dla zbioru dokumentów. Na końcu został zamieszczony wykres, z którego można odczytać jak zmienia się wartość topic coherence dla różnej ilości tematów.
import pandas as pd
from tqdm import tqdm
from gensim import models, corpora
from ggplot import *
%matplotlib inline
def lda(corpus,id2word,dataset,topic_num):
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word, num_topics=topic_num,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
coherence_model_lda = CoherenceModel(model=lda_model, texts=dataset, dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
topics = lda_model.print_topics(-1)
return coherence_lda, topics, lda_model
def find_topics(start, end, dataset):
id2word = corpora.Dictionary(dataset)
corpus = [id2word.doc2bow(text) for text in dataset]
coherence_array = []
topics_array = []
topic_range = range(start,end)
lda_model_array = []
for topic_num in tqdm(topic_range):
coherence_lda, topics, lda_model = lda(corpus,id2word,dataset,topic_num)
topics_array.append(topics)
coherence_array.append(coherence_lda)
lda_model_array.append(lda_model)
return {'coherence_array': coherence_array, 'topics_array': topics_array, 'lda_model_array':lda_model_array, 'corpus':corpus, 'id2word':id2word, 'topic_range':topic_range}
results = find_topics(5,50,dataset_temp)
coherence_plot_pd = pd.DataFrame({'y_data': results['coherence_array'], 'x_data': results['topic_range']})
ggplot(aes(x='x_data', y='y_data'), data=coherence_plot_pd) + geom_line()
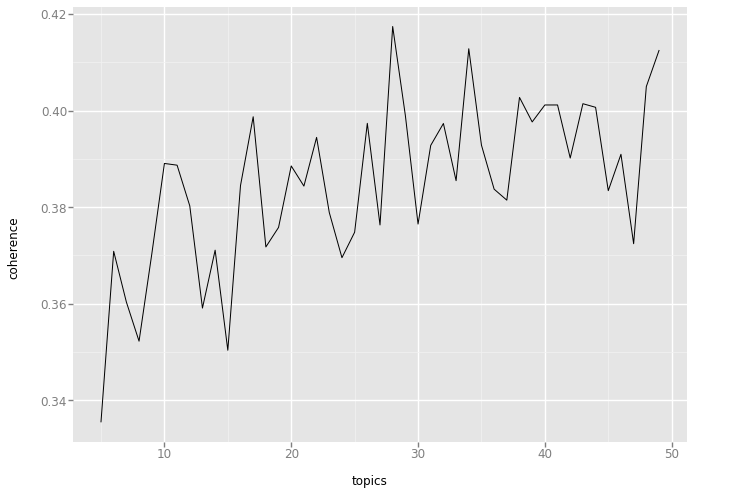
Z powyższego wykresu można odczytać, że największa wartość topic coherence jest dla modelu z 28 tematami.
pyLDAvis
pyLDAvis powstał, aby ułatwić użytkownikom interpretacje znalezionych przez algorytm tematów. Jest to najlepsza metoda do zobrazowania dystrybucji tematów – słów kluczowych.
Biblioteka wyodrębnia informacje z powstałego modelu LDA, aby stworzyć interaktywną wizualizację:
Dobry model będzie tu zawierał jak najmniej nakładających się na siebie obiektów, o stosunkowo dużych rozmiarach dla każdego tematu.
Wnioski
Latent Dirichlet Allocation to najpopularniejszy algorytm topic modeling. Pozwala on na wykrycie poruszanych tematów w nieustrukturyzowanych dokumentach. Algorytm znajduje swoje zastosowanie w grupowaniu tekstów, wyszukiwaniu informacji (information retrieval) oraz w wykrywaniu trendów.
Dobrym sposobem porównywania różnych modeli LDA w oparciu o ich interpretowalność jest topic coherence. Otrzymane wyniki można łatwo zwizualizować dzięki bibliotece pyLDAvis.
Jak możesz wykorzystać AI dla swojego biznesu?