Wie funktionieren maschinelle Lernalgorithmen?
Am Beispiel von LIME und der Interpretierbarkeit von Modellen

Krzysztof Udycz
KI-Ingenieur
24. Juni 2019
Maschinelles Lernen und künstliche Intelligenz haben bereits in vielen unserer Lebensbereiche Einzug gehalten. Unsere Smartphones nutzen Sprachassistenten, es werden uns Produkte online zum shoppen oder Videos vorgeschlagen, die entsprechend unserer persönlichen Vorlieben herausgesucht wurden. Sie machen ihren Job gut und wir nehmen sie kaum wahr, aber es ist ein beidseitiges Geschäft. Mit der Nutzung dieser Dienste und beim Auswählen der vom Algorithmus vorgeschlagenen Lösungen geben wir eine Art von Vertrauensbezeugnis in diese Entscheidungen ab. Es ist zu beachten, dass Modelle wie zufällige Wälder oder tiefe neuronale Netze Klassifikatoren (Algorithmen zur Bestimmung der Entscheidungsklasse von Objekten) sind, die Tausende von Faktoren berücksichtigen. Sie sind so groß, dass es leicht ist, die Kontrolle über das Ergebnis ihres Lernens und die Gründe für die erzeugten Vorhersagen zu verlieren.
Die Blackbox der KI oder wie maschinelle Lernalgorithmen funktionieren
Um die Funktionsweise von maschinellen Lernalgorithmen leicht zu erklären, stellen Sie sich eine Blackbox vor. Algorithmen führen Aktionen für die Eingabedaten durch, um ein bestimmtes Ergebnis zurückzugeben. Sie sind jedoch nicht in der Lage, zu erklären, wie die Entscheidung getroffen wurde. Sie stellen eine Konfiguration dar, die wir nicht komplett überblicken können, als wäre sie in einer Blackbox eingeschlossen. Das Bestreben danach es zu verstehen, auf welcher Grundlage diese Prognosen gemacht werden, eines der wichtigsten Schlüsselelemente bei der Entwicklung von künstlichen Intelligenz-Anwendungen. Die Entwickler müssen sicher sein, dass das Modell gut mit realen Daten und nach wertvollen Metriken funktioniert. Wenn es nicht vertrauenswürdig ist, sollte es nicht verwendet werden.
Interpretierbarkeit von Modellen und Systemen des maschinellen Lernens
Sie hilft komplexe Modelle (erklärbare künstliche Intelligenz) zu erklären. Das ist besonders wichtig, wenn die Entscheidungen der KI einen Menschen direkt betreffen. Es zielt darauf ab, Klassifizierungsmerkmale zu erstellen, die:
- Eine gültige Erklärung dafür liefern, wo und wie künstliche Intelligenzsysteme Entscheidungen treffen
- Die Lerneffizienz der Algorithmen erklären, derzeit sind Modelle mit einer hohen Vorhersagegenauigkeit schlecht interpretierbar
- Sowohl Ergebnisse als auch Vorhersagen gleichzeitig generiert
Warum ist erklärbare künstliche Intelligenz so wichtig?
Wie ich bereits erwähnt habe, gibt es eine Reihe von Gründen, warum die “Erklärbarkeit” der künstlichen Intelligenz so wichtig ist. Dazu gehören unter anderem:
- Vertrauensbildung – Können wir darauf vertrauen, dass unsere Vorhersagen richtig sind? Können Modelle, die wir nicht verstehen, Menschen verletzen?
- Kontrolle – Wissen wir genau, wie sich unser KI-System verhält?
- Sich sicher fühlen – Kann jede Entscheidung mit den Sicherheitsbestimmungen und Warnungen vor Verstößen erklärt werden?
- Vorhersagebewertung – Können wir das Verhalten des Modells verstehen? Sind die Erklärungen ausreichend? Verhalten sich unsere Daten wie erwartet?
- Verbesserung und Erweiterung des Modells – Wie können wir unsere Klassifizierung auf der Grundlage der Erklärungsansätze nachvollziehen, bewerten und möglicherweise verbessern?
- Bessere Entscheidungsfindung – Ist unser Modell intelligent? Können wir dank der Erklärungen bessere Entscheidungen treffen?
Aus technischer Sicht ist die Erklärbarkeit von maschinellen Lernsystemen entscheidend, da sie ein Gefühl der Kontrolle und Sicherheit vermittelt und es uns ermöglicht, festzustellen, ob sich unser Modell korrekt verhält.
Darüber hinaus schafft es Vertrauen bei den Kunden, die die Gründe für die KI Entscheidungen überprüfen können, um festzustellen, ob sie die Rechtsvorschriften (wie RODO / GDPR), einhalten können.

Only 1 mistake!

The results of the classifier recognizing whether there is a wolf or a husky dog in the photo. Source: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
Let’s look at the example above. It shows the result of the classifier recognizing whether there is a wolf or a husky dog in the photo. You can see that this is a system of high precision prediction – it was wrong only once. The model stated that there was a wolf in the lower left corner of the photo, although in reality it is a husky dog. The remaining images were classified correctly.
So the question is: “Which approach is better?”. Blindly believing in the correctness of the model and based only on the quality of the predictions, or trying to explain on what basis the decisions were made?

The results of the classifier recognizing whether the photo contains a wolf or a husky dog and the information on which part of the image the model made the decision. Source: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
On the illustration above we see which parts of the picture were informative for our classifier. It turns out that instead of wolves, it detects snow! If not for the approach to explainability of artificial intelligence models, we would not know that decisions were made on the basis of the wrong parts of the photo.
So the answer is: don’t trust the model blindly! Without knowing on what basis it makes its choices, we don’t know if it’s the right signal, noise or background. So the key is to try to understand how it works and to generate explanations.
LIME - Local Interpretable Model-Agnostic Explanations
The LIME framework comes in handy, whose main task is to generate prediction explanations for any classifier or machine learning regressor.
This tool is written in Python and R programming languages. Its main advantage is the ability to explain and interpret the results of models using text, tabular and image data.
Classifier and regressor - do you know these terms?
The classifier predicts from a defined set a class or category for a given observation, e.g., an e-mail message can be marked with one of two classes: “spam’ or ‘ham’ (a word that is not spam).
The regressor however, tries to estimate the real value – an integer or a floating point. This number is not previously defined in any set, for example, predicting the amount for which the house will be sold we can get the amount from the range of PLN 400,000 to PLN 700,000.
The explanation of the acronym “LIME” indicates the key attributes of this acronym:
- Local – uses locally weighted linear regression,
- Interpretable Explanations – allows you to understand what a model does, which features it chooses to create a classifier,
- Model-Agnostic – treats the model as a black box.
How does LIME work?
The explanation is generated by bringing the original model (black box) closer to the explained model (such as linear classifier with several non-zero parameters). The interpretable model is created on the basis of the perturbation of the original instance from which the selected components were excluded. This can be for example removing words or hiding a part of an image.
Imagine that you want to explain a classifier that predicts how likely it is that a tree frog is in the image. The first step is to divide the image into interpretable parts.

Transformation of the image of a tree frog into interpretable components. Source: Marco Tulio Ribeiro.
Then we modify the image in a number of ways to enable or disable some of the interpretable components (in the case of this image, the excluded areas are grayed out). For each of the generated images the probability of a tree frog’s presence on it (according to our model) is obtained.
The next step is to learn a linear model weighed locally on the received dataset, so we can understand how it behaves in a small local environment. As the final result of the algorithm (explanation of the original model), the components with the highest weights are presented.
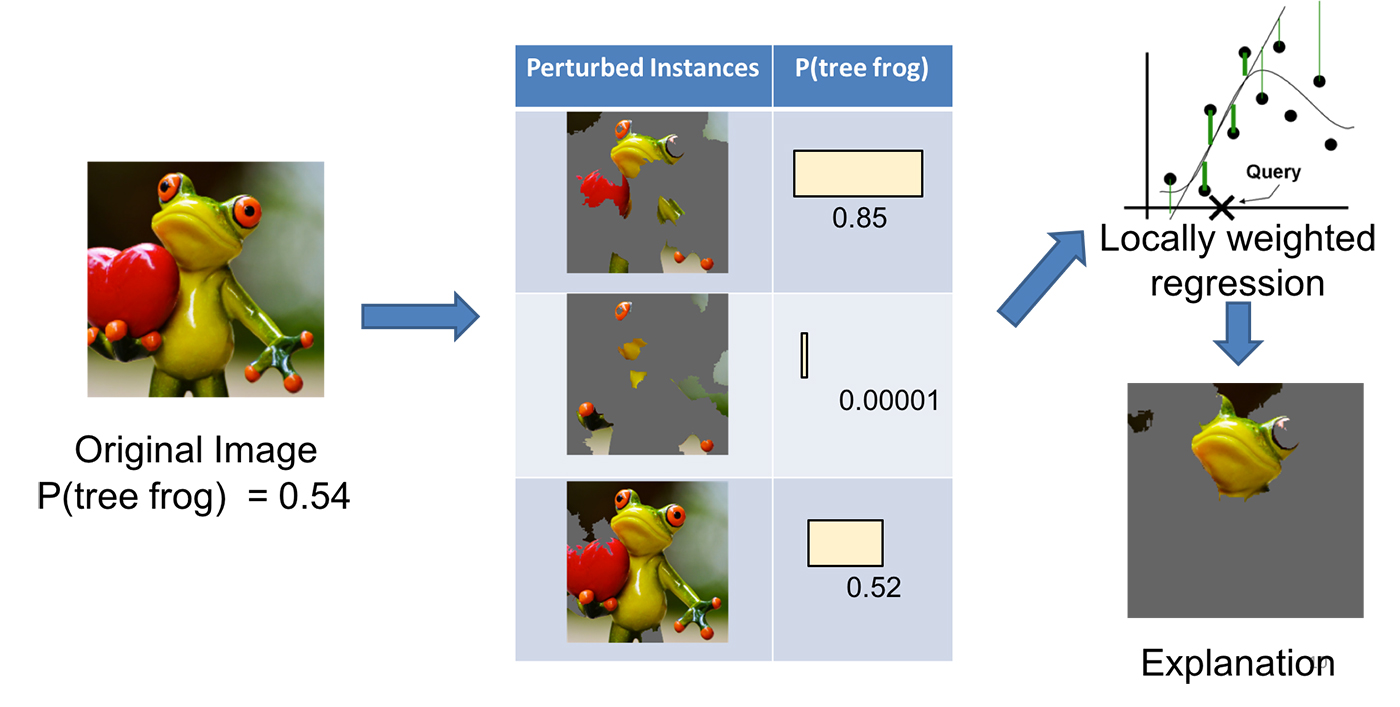
Schematics for generating model explanations using the LIME framework. Source: Marco Tulio Ribeiro.
LIME - use case
20 Newsgroup dataset is a collection of about 20,000 documents divided into 20 topics from discussion groups (e.g. sport, Christianity, atheism or electronics). It is one of the most popular data sets used in natural language processing (NLP).
Let us assume that we have created a classification of random forests, which distinguishes which of the two thematic groups (Christianity or atheism) a given text belongs to. Below is a code that can be used to generate explanations for the text.
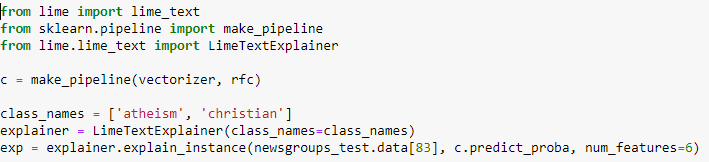
An exemplary text from 20 Newsgroup datasets for which explanations will be generated. Source: Marco Tulio Ribeiro.
A code representing the generation of explanations using LIME. Source: Marco Tulio Ribeiro.
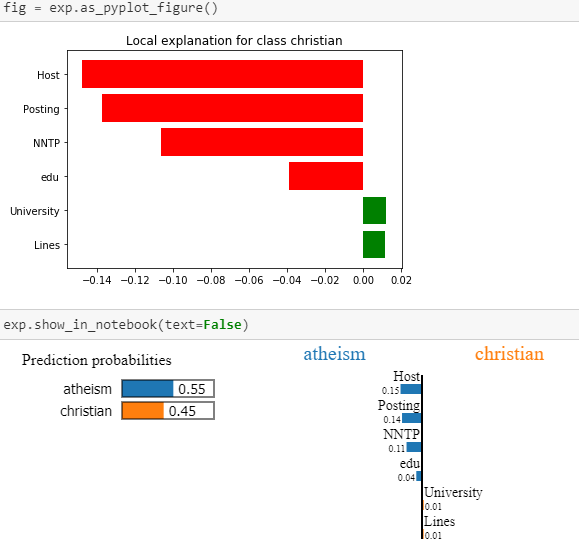
Explanations generated with LIME. Source: Marco Tulio Ribeiro.
It can therefore be seen that, in the case of the above text, the model assumes belonging to the class “atheism” mainly on the basis of words: Host’, ‘Posting’, ‘NNTP’ or ‘edu’.
However, LIME is not the only framework we can use to interpret models. They also include, for example:
- DALEX https://github.com/pbiecek/DALEX
- SHAP https://github.com/slundberg/shap
- ELI5 https://eli5.readthedocs.io/en/latest/
- RandomForestExplainer (R package)
- XgboostExplainer (R package)
Example of application of interpretability of artificial intelligence models and systems in business and science
The interpretability of the models has proven its value in many areas of business and scientific activities, such as:
- Detection of unusual behaviours – identification and explanation of events and unusual behaviours,
- Detection of fraud – to identify and explain why certain transactions are treated as frauds,
- Opinion on loans and credits – identification and explanation of why a certain customer will be able to pay off debt and another will not,
- Marketing campaigns, targeting of advertisements – increasing the accuracy of offers and messages and matching the content to the true and most important interests of merchants,
- Medical diagnostics,
- Automation of vehicles,
- And many others.
Machine learning and artificial intelligence models are used in many areas of our lives, such as medicine, law, transport, finance and security. Considering that they very often have a direct impact on humans, it is very important to understand on what basis they make decisions. A technique that deals with the explanation of complex AI models comes to the assistance then.
Do you want to take advantage
of artificial intelligence in your company?
")