The Rise of Multimodal Models: Beyond Single-Sense AI Solutions

Agata Chudzińska
AI Manager
08. November 2023
In the intricate landscape of artificial intelligence, the emergence of multimodal models stands out as a significant evolution. As AI continues to inch closer to human-like cognition, understanding the multifaceted nature of these models is crucial for both enthusiasts and businesses alike.
What is a Multimodal AI?
At its core, every human being perceives the world using multiple senses. From the visuals we see to the sounds we hear, and the textures we feel – every sense plays a role in giving us a complete picture of our environment. Multimodal AI seeks to mimic this comprehensive sensory experience. It does so by processing a variety of data types simultaneously, whether it’s textual content, visual imagery, or audio inputs. The result? A richer and more detailed understanding of information, much like how we, as humans, perceive the world.
The AI realm isn’t unfamiliar with models that can handle images or text. Early models could analyze an image and generate a relevant caption. However, modern multimodal models, like GPT-4V (or the newly announced GPT-4 Turbo) and others, have raised the bar. They are designed for bi-directional tasks, such as converting textual descriptions into visual imagery and vice versa, showcasing a more dynamic approach to data interpretation. A truly fascinating capability of the new multimodal models is the possibility of interleaving of texts and images – allowing you to very flexibly combine images and texts in your prompts during the conversation. Example of it is shown in the below image:
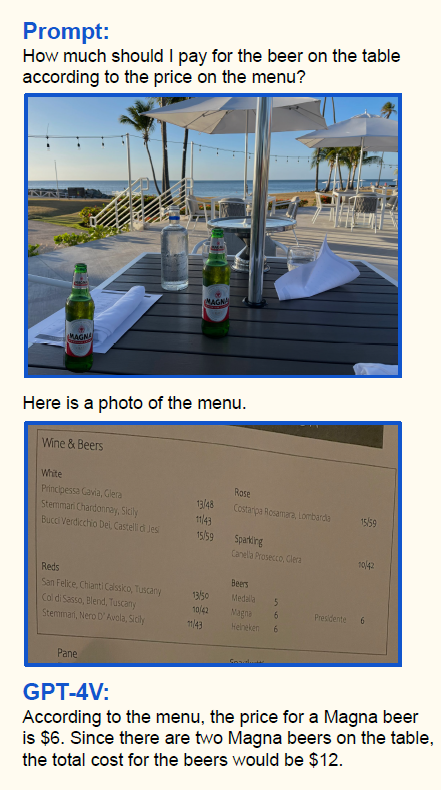
On the presented example, we can not only see that the model has correctly recognized the name and amount of the beers on the first picture, but in the same request it analyzed the content of the menu on the second picture and combined information from both pictures to answer the question, which is really impressive.
Real-world Applications of Multimodal Models
Multimodal models have potential applications across numerous sectors. Exemplary use cases include:
- E-commerce: Merging textual reviews with product images for richer product understanding.
- Healthcare: Integrating medical images with patient notes for comprehensive diagnoses.
- Entertainment: Customizing content based on both textual and visual user preferences.
As you can see the use cases of multimodal applications can be very broad, and with the recent release of the OpenAI’s GPT-4 Turbo with the Vision API we can expect to see many new scenarios that will support us at daily tasks as well as automating the business activities.
The Future Landscape of Multimodal AI
The trajectory of AI points towards more integrated, multisensory models. As research progresses, the AI community anticipates solutions that not only mimic but also enhance human-like data processing. There are already first approaches toward combining more modalities, such as videos, audio and even 3D data for a more holistic approach.
While GPT-4V has garnered attention, it’s one of many in the expanding universe of multimodal models. Similarly like in case of Large Language Models (LLM) the area of Large Multimodal Models (LMM) the field is quickly approaching with open source alternatives with models like LLaVa also focusing on the multimodal capabilities. As AI continues to evolve, it’s essential to stay informed about various models and their unique capabilities.
Conclusion
Multimodal AI models represent the next frontier in artificial intelligence. By offering a more holistic approach to data processing, they promise to revolutionize how we understand and interact with technology.
If you’re keen on exploring and deploying generative AI solutions based on these advanced models, feel free to reach out. Our team is equipped with the expertise to help you navigate this exciting frontier in AI.
Sources:
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, Lijuan Wang, The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision), 2023, https://arxiv.org/abs/2309.17421
OpenAI, GPT-4V(ision) System Card, 2023, https://cdn.openai.com/papers/GPTV_System_Card.pdf
LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
Who we are
At theBlue.ai, we specialize in developing intelligent AI solutions tailored to the specific needs and requirements of businesses. With our expertise in AI, we can craft custom solutions, designed to enhance productivity and improve efficiency across various business sectors. Contact us to start your own project.
")