Was ist Retrieval Augmented Generation (RAG), und warum sollten Sie es in Ihrem Unternehmen einsetzen?

Kamil Koligot
AI Engineer
25. September 2023
In der heutigen Zeit von Big Data und künstlicher Intelligenz verändern Large Language Modelle (LLMs) die Art und Weise, wie wir mit unseren Datenressourcen umgehen und mit ihnen interagieren können. Sie eröffnen uns neue Möglichkeiten für intelligente Datenverarbeitungstechniken und machen es Benutzern einfacher, Dokumente durch die Verwendung anspruchsvoller Fragen schneller zu analysieren. Dies erleichtert den Prozess des Wissenserwerbs und der Entscheidungsfindung erheblich.
Da Unternehmen und Organisationen heutzutage eine riesige Menge an Daten und Dokumenten ansammeln, wird immer deutlicher, dass wir dringend bessere Werkzeuge benötigen, um all diese Informationen zu organisieren, zu durchsuchen und optimal zu nutzen. Das ist genau der Punkt, an dem die Retrieval Augmented Generation (RAG) ins Spiel kommt. Sie stellt eine kraftvolle Methode dar, um unsere Modelle durch kluge Fragen und erweiterte Suchmöglichkeiten mit frischem Wissen zu versorgen. Das bedeutet, dass Mitarbeitern die mühsame Aufgabe des Durchwühlens von Dokumentenstapeln erspart bleibt. Das klingt doch wirklich vielversprechend, oder?
In diesem Artikel werden wir einen genaueren Blick auf die Funktionsweise des RAG-Systems werfen. Wir werden seine Bestandteile genauer beleuchten, die Hauptvorteile, die es mit sich bringt, hervorheben und mögliche Herausforderungen erörtern.
Was ist Retrieval Augmented Generation (RAG)?
Lassen Sie uns einen näheren Blick auf Retrieval Augmented Generation (RAG) werfen. RAG ist eine Methode, die Anfragen durch das Einbeziehen von Kontext und relevanten Informationen aus externen Datenquellen verbessert. Diese Technik erweitert die Fähigkeiten großer Sprachmodelle (LLMs) erheblich, insbesondere wenn es darum geht, mit maßgeschneiderten Daten zu arbeiten.
LLMs, wie das weitverbreitete GPT-Modell, sind zweifellos fortgeschritten. Dennoch haben sie eine gewisse Einschränkung. Sie verfügen nicht über spezifisches Wissen zu bestimmten Themen und verlassen sich in erster Linie auf das, was sie während ihres Trainings gelernt haben. Dieses Wissen ist begrenzt und ändert sich nicht im Laufe der Zeit, was bedeutet, dass sie nicht in der Lage sind, neue Informationen oder Entwicklungen in speziellen Themengebieten aufzunehmen.
Hier kommt RAG ins Spiel. Es kombiniert Techniken zur Informationsabfrage mit Textgenerierung. Vereinfacht ausgedrückt ermöglicht es Ihrem KI-System, Inhalte basierend auf dem zu erstellen, was es in einer benutzerdefinierten Datenbank oder einer Sammlung von Texten findet. Das ultimative Ziel besteht darin, die Leistung der vorab trainierten LLMs wie GPT mit frischem Wissen aus Textquellen zu verbinden.
GPT ist eines der führenden Modelle auf dem Markt. RAG geht einen Schritt weiter, indem es GPT die Fähigkeit verleiht, neues Wissen aus relevanten Dokumenten zu absorbieren.
Um die Leistung von KI in einem bestimmten Bereich zu verbessern, war das Feintuning der übliche Ansatz. Feintuning beinhaltet zusätzliches Training mit neuen Daten, was zeitaufwändig und kostenintensiv sein kann.
RAG bietet jedoch einen anderen Ansatz. Es ergänzt Ihre Anfragen um zusätzlichen Kontext mit relevanten Informationen. Stellen Sie sich das vor wie einen kontinuierlichen Wissensboost. Dieser dynamische Ansatz ermöglicht es den Modellen, auf einen ständig wechselnden Pool von Daten zuzugreifen, um genauere Antworten zu liefern.
Das Beste daran? Es verringert die Notwendigkeit für häufiges Modelltraining und spart sowohl Zeit als auch Rechenressourcen.
Beim RAG-Ansatz können wir zwei Hauptphasen unterscheiden:
- Abrufphase
- Generieungsphase
Abrufphase: Nachdem eine Eingabe-Abfrage eingegangen ist, durchsuchen die Modelle einen Textkorpus oder eine Datenbank nach Informationen oder Dokumenten, die die benötigten Antworten enthalten könnten.
Generierungsphase: In dieser Phase generiert das System Antworten auf der Grundlage des abgerufenen Textes. Während dieses Schritts kombiniert das Modell die gefundenen Informationen mit seinem grundlegenden Verständnis, das es während seiner Trainingszeit erworben hat.
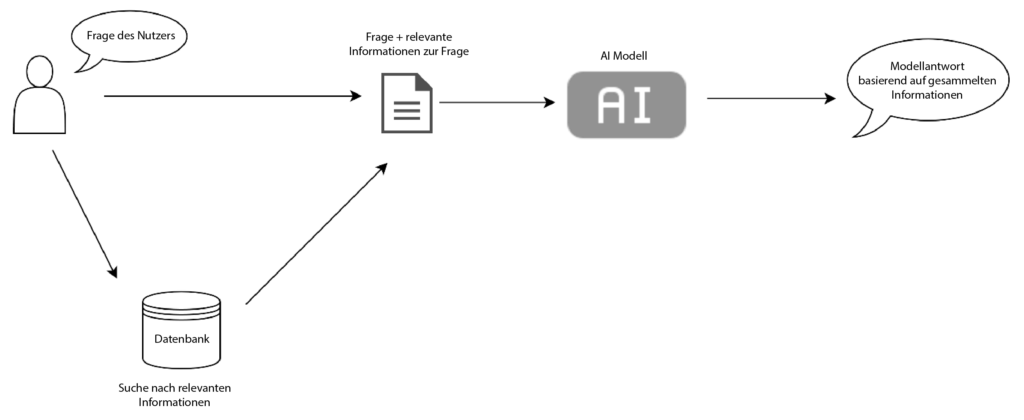
Das Diagramm oben veranschaulicht, wie das RAG-System arbeitet. Alles beginnt mit den Fragen der Benutzer, die dann in einem nächsten Schritt verarbeitet werden, um die Suche effizienter zu gestalten.
Das System sucht dann in einer vordefinierten Sammlung von Texten oder einer Datenbank nach den relevantesten Informationen, die wir benötigen.
Bei der Informationssuche geht das System über einfache Schlüsselwortübereinstimmungen hinaus. Es verwendet eine intelligente Methode, die als semantische Suche bekannt ist und dabei hilft, verwandte Informationen besser zu finden. Denken Sie daran, wie Sie in einer Bibliothek ein Buch nicht nur anhand seines Titels, sondern auch anhand seines Themas finden. Dabei spielen Tools wie Vektordatenbanken eine wichtige Rolle. Hier können Sie mehr über Vektordatenbanken erfahren: mehr erfahren.
Die Fragen der Benutzer und die möglichen Antworten, die während der Suche gefunden werden, werden kombiniert, um dem Modell bei der Erstellung der endgültigen Antwort zu helfen.
Vorteile und Herausforderungen
Einer der Hauptvorteile von RAG-Systemen ist ihre dynamische Wissensgrundlage. Diese Systeme ermöglichen Modellen den Zugriff auf eine Wissensquelle, die sich im Laufe der Zeit aktualisiert und erweitert. RAG-Systeme finden in der Praxis Anwendung im Kundenservice, wo sie schnelle und präzise Antworten auf Benutzerfragen basierend auf aktuellen Informationen oder Kenntnissen zu speziellen Themen bieten, sowie in der Content-Erstellung, beispielsweise bei der Erstellung maßgeschneiderter Berichte.
Es gibt jedoch einige Herausforderungen bei der Entwicklung von RAG-Systemen. Eine dieser Herausforderungen besteht darin, sicherzustellen, dass die während des Suchprozesses abgerufenen Daten tatsächlich relevant sind. Darüber hinaus erfordert der Abrufschritt oft die Integration zusätzlicher Komponenten wie einer Vektordatenbank in das System. Obwohl diese Komponenten wertvoll sein können, besteht die Möglichkeit, dass sie die Antwortzeiten erhöhen und kontinuierliche Wartung erfordern. Die Schaffung effizienter RAG-Systeme erfordert ein tiefes Fachwissen und Erfahrung in diesem Bereich.
Fazit
RAG-Systeme bieten eine innovative Herangehensweise zur Verwaltung von Textinformationen und zur Entwicklung von KI-Systemen, die maßgeschneiderter und flexibler sind. Sie helfen dabei, das Wissen in den Modellen durch das Einbinden aktueller Informationen aus individuellen Dokumenten zu erweitern. Diese Methode kombiniert die Leistungsfähigkeit großer Sprachmodelle wie GPT mit der Fähigkeit, dynamisch auf individuelle Daten zuzugreifen. RAG verspricht, die Genauigkeit und Relevanz individueller Daten erheblich zu verbessern und eröffnet gleichzeitig Möglichkeiten zur Schaffung robusterer Systeme.
Wenn Sie Interesse daran haben, Retrieval Augmented Generation (RAG) Systeme für Ihre Prozesse zu nutzen, zögern Sie nicht, uns zu kontaktieren. Wir sind hier, um Ihnen zu helfen.
