Multi-label classification. Charakterystyka i zastosowania.

Michał Klimas
Inżynier Machine Learning
24 października 2018
Dzięki tej metodzie możesz zautomatyzować procesy i znacznie zaoszczędzić czas. Pozwala ona na etykietowanie plików tekstowych, dźwiękowych oraz wideo.
Zajmujesz się handlem elektronicznym, dostajesz zbyt wiele e-maili… Jesteś przytłoczony informacjami politycznymi i gubisz się w dokumentach prawnych.
Chcesz śledzić trendy społeczne, aby nadążać za swoją pracą. Chcesz optymalnie wybrać nazwę dla nowego produktu. A może pracujesz w przemyśle farmaceutycznym i chcesz sprawdzić, jak nowe leki wpływają na klientów?
Teraz możesz zautomatyzować te procesy i zaoszczędzić czas dzięki tzw. Multi-label classification. Pozwala ono na etykietowanie plików tekstowych, dźwiękowych i wideo. Elementy te mogą jednocześnie należeć do kilku tematów i w rezultacie mogą mieć wiele znaczników/etykiet.
Z tego artykułu dowiesz się:
- Jakie są zastosowania multi-label classification w różnych branżach
- Jakie są najczęstsze problemy wynikające z korzystania z tej techniki?
- Jak je rozwiązać?
- Jak biznes wykorzystuje multi-label classification?
Zastosowanie multi-label classifiaction
Ta technika uczenia maszynowego ma wiele zastosowań w różnych gałęziach przemysłu. Dzięki przypisywaniu różnych znaczników i etykiet, możemy uzyskać następujące korzyści:Zajmujesz się handlem elektronicznym, dostajesz zbyt wiele e-maili… Jesteś przytłoczony informacjami politycznymi i gubisz się w dokumentach prawnych.
Chcesz śledzić trendy społeczne, aby nadążać za swoją pracą. Chcesz optymalnie wybrać nazwę dla nowego produktu. A może pracujesz w przemyśle farmaceutycznym i chcesz sprawdzić, jak nowe leki wpływają na klientów?
Teraz możesz zautomatyzować te procesy i zaoszczędzić czas dzięki tzw. Multi-label classification. Pozwala ono na etykietowanie plików tekstowych, dźwiękowych i wideo. Elementy te mogą jednocześnie należeć do kilku tematów i w rezultacie mogą mieć wiele znaczników/etykiet.
Z tego artykułu dowiesz się:
- Jakie są zastosowania multi-label classification w różnych branżach
- Jakie są najczęstsze problemy wynikające z korzystania z tej techniki?
- Jak je rozwiązać?
- Jak biznes wykorzystuje multi-label classification?
Zastosowanie multi-label classifiaction
Ta technika uczenia maszynowego ma wiele zastosowań w różnych gałęziach przemysłu. Dzięki przypisywaniu różnych znaczników i etykiet, możemy uzyskać następujące korzyści:





Tworzenie profili 360° użytkowników
Może to być punktem wyjścia dla szeregu działań związanych z marketingiem lub sprzedażą. Przykładem takiego zastosowania mogłoby być np. stworzenie profilu klienta, który jest zarówno użytkownikiem Apple, jak i fanem sportu.
Tworzenie systemu rekomendacji
Wcześniej utworzony profil użytkownika może być podstawą do tworzenia systemu rekomendacji, np. w programach lojalnościowych lub sklepach internetowych.
Targetowanie w mediach społecznościowych
Takie profile mają również inne zastosowanie, które wykorzystuje je do adresowania przekazu do konkretnych odbiorców w mediach społecznościowych. Może ono obejmować działania promocyjne, content marketing lub tzw. social selling.
Automatyczne wykrywanie niepożądanych reakcji na leki na podstawie danych tekstowych
Multi-label classification jest również bardzo przydatna w przemyśle farmaceutycznym. Dane zebrane ze źródeł takich jak np. Twitter, opisujące reakcje na leki, mówią wiele o działaniach niepożądanych. Przetwarzanie tych informacji za pomocą określonych algorytmów może przynieść zaskakujące wyniki.
Automatyczne rozpoznawanie opinii i odczuć
Opisana metoda wydaje się być bardzo przydatna w tworzeniu wyrafinowanej analizy wydźwięku. Firmy wykorzystują ją do przeprowadzania szczegółowych badań opinii klientów na temat ich produktów.
Problemy związane z multi-label classification
Korzystając z opisanego rozwiązania możemy napotkać ewentualne problemy:
- bardzo nierównomierny zestaw danych – każda etykieta może wystąpić w innej liczbie, każdy dokument (tekst, zdjęcie, próbka dźwiękowa, wideo) ma inną liczbę etykiet
- różna długość dokumentu – dla problemu klasyfikacji tekstu większość algorytmów ML wymaga, aby dokumenty miały jednakową długość
- wiele wskaźników do wyboru
Jak rozwiązać problemy związane z multi-label classification?
Możemy rozważyć dwa możliwe podejścia. Jedno z nich to klasyczne rozwiązanie machine learning wykorzystujące biblioteki sklearn lub scikit-multilearn, a drugie – algorytmy deep learning.
Po pierwsze, musimy przeprowadzić eksploracyjną analizę danych (EDA). Czyli innymi słowy: poznać strukturę danych, ustalić liczbę etykiet, ocenić czy dane są zrównoważone czy nie, sprawdzić brakujące dane, policzyć ile występuje obserwacji nieoznakowanych, a także poznać dystrybucję danych i podstawowe statystyki opisowe, dyspersję i kształt zbiorów danych.
Najważniejsza jest faza wstępnego przetwarzania tekstu. Składa się ona z wielu etapów, takich jak:
- Czyszczenie tekstu – usuwanie niepożądanych słów (tzw. stop words, interpunkcja, białe spacje, znaczniki HTML i inne)
- Stemming – redukcja słowa do samego tematu (odcięcie przyrostka, przedrostka)
- Lematyzacja – zwraca podstawową formę słowa
Dla wszystkich powyższych możemy rozważyć użycie bibliotek: nltk, spacy, pandas, lxml i innych.
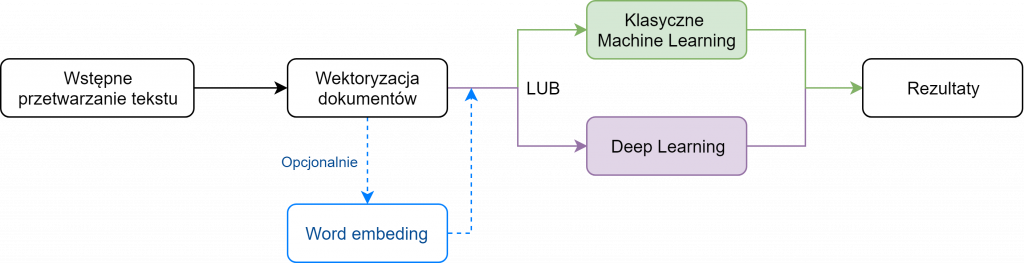
Pod pojęciem wektoryzacji dokumentów, rozumiemy przekształcanie/mapowanie tekstu na binarną macierz tokenów. W tym celu możemy zastosować CountVectorizer z biblioteki scikit-learn z określonymi parametrami token_pattern, ngram_range i innymi. Dla dłuższych i bardziej złożonych dokumentów wskazane jest użycie transformacji TF-IDF, gdzie mierzone jest podobieństwo pomiędzy termami i dokumentami.

Word embedding to model, które może odtworzyć językowy kontekst słów w zdaniu. Proces polega na mapowaniu słów do wektorów liczb. Przykładami algorytmów osadzania słów są algorytmy Word2vec, Glove, Fasttext, gdzie możemy używać już wyuczonych modeli lub “wytrenować je” samemu.
Klasyczne podejście do uczenia maszynowego może być wykonane przy użyciu jednego z podanych klasyfikatorów:
biblioteka sklearn:
- OneVsRestClassifier,
- RandomForestClassifier,
- MultinominalNB,
- lub inne, wspierające multi labeling (więcej tutaj)
biblioteka scikit-multilearn:
- BinaryRelevance,
- ClassifierChains,
- LabelPowerset,
- ML-KNN (multi-label lazy learning).
Dla podejścia Deep learning:
- RNN (rekurencyjna sieć neuronowa) wraz z LSTM (Long-short term memory),
- 2D CNN (konwolucyjna sieć neuronowa), gdzie w ostatniej warstwie funkcją aktywacji jest sigmoid, a funkcją kosztu binary cross_entropy.
Wskaźniki:
- Micro-averaging – sklearn.metrics.f1_score(average=’micro’),
- Macro-averaging – sklearn.metrics.f1_score(average=’macro’),
- Hamming-Loss – sklearn.metrics.hamming_loss
- Jaccard similarity coefficient – sklearn.metrics.jaccard_similarity_score
- AUC – sklearn.metrics.roc_auc_score
- Exact Match Ratio – sklearn.metrics.accuracy_score
Jak je wykorzystać w Twojej branży?