Multi-label classification
Overview

Michał Klimas
Machine Learning Engineer
October 16, 2018
Now you can automate processes and save time through multi-label classification. It allows to label text, sound and video files. Those elements may simultaneously belong to several topics and in result have multiple tags/labels.
You handle e-commerce, get too many e-mails… You are overwhelmed by the political information and you get lost in legal documents.
You want to track social trends to keep up with your work. You want to optimize a branding of a new product. Maybe you work in the pharmaceutical industry, and you want to check how new drug impacts customers.
Now you can automate those processes and save time through multi-label classification. It allows to label text, sound and video files. Those elements may simultaneously belong to several topics and in result have multiple tags/labels.
From this article you will learn:
- What are the applications of multi-label classification in various industries?
- What are the most common issues with this technique?
- How to solve them?
- How business uses multi-label classification?
Multi-label classification applications
This machine learning technique has multiple applications in a spectrum of industries. Thanks to assigning various tags and labels, we can gain the following results:
 Creating 360 user profiles
Creating 360 user profiles
This can be a starting point for a spectrum of activities connected with marketing or sales and other. Example of such application is creating a profile of a customer which is both Apple user and a sport fan.
Building a recommendation system
A previously created user profile can be a base to making recommendation system, i.e., in loyalty programs or e-commerce stores.
Social media targeting
Such profiles also have another application which is using them to target the specific audience in social media. This can include promotion, content marketing activities or social selling.
Automatically detecting adverse drug reaction from text
Multi-label classification is also very useful in the pharmaceutical industry. Data gathered from sources like Twitter, describing reactions to medicines says a lot about the side effects. Processing this information through the specific algorithms can provide surprising results.
Recognizing opinions and sentiments automatically
The described method appears to be very useful in creating a sophisticated sentiment analysis. Companies use it to perform detailed research about customer feedback on their products.
Multi-label classification issues
During handling described problem possible issues may happen:
- highly imbalanced dataset – each label may occur with a different number, each document (text, photo, sound sample, video) has a different number of labels,
- different length of a document – for text classification problem most of the ML algorithms require documents to have equal length,
- multiple metrics to choose.
How to solve text multi-label classification problems?
We can consider two possible approaches. One which takes classic ML solution using sklearn or scikit-multilearn libraries or second one using deep learning algorithms.
Firstly, we need to perform exploratory data analysis (EDA). Meaning to feel the data structure, check the number of labels, check data integrity whether is balanced or not, check missing data, count how many unlabeled observations are present, see data distribution and basic descriptive statistics, dispersion, and shape of data sets.
Text preprocessing phase is the most important one. It consists of many steps such as:
- Text cleaning – unwanted words removal (stop words, punctuation, white space, HTML tags and more),
- Stemming – reduce a word to its stem (chop off suffix, prefix)
- Lemmatization – return the base form of a word.
For all above we can consider using libraries: nltk, spacy, pandas, lxml and others.
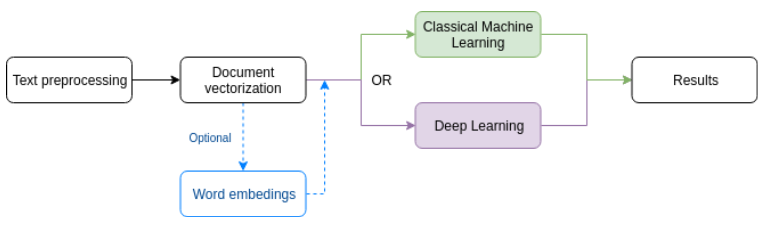
For document vectorization, we understand text transforming/mapping to a binary matrix of tokens. For this, we can apply CountVectorizer from the scikit-learn library with specific token_pattern, ngram_range, and other parameters. For longer and more complex documents it is advisable to use TF-IDF transformation where the similarity between queries and documents is measured.

Word embeddings are models that can reconstruct linguistic contexts of words in a sentence. The process involves mapping words to vectors of numbers. Examples of word embeddings algorithms are Word2vec, Glove, Fasttext, where we can use already trained models or pretrain on our own.
Classical Machine Learning approach can be done using one of given classifiers:
sklearn library:
- OneVsRestClassifier,
- RandomForestClassifier,
- MultinominalNB,
- or different one which supports multi labeling (more here).
scikit-multilearn library:
- BinaryRelevance,
- ClassifierChains,
- LabelPowerset,
- ML-KNN (multi-label lazy learning).
For Deep learning approach:
- RNN (recurrent neural network) with LSTM (Long-short term memory),
- 2D CNN (convolutional neural network) with sigmoid as last layer activation function and binary cross_entropy as a loss function.
Metrics:
- Micro-averaging – sklearn.metrics.f1_score(average=’micro’),
- Macro-averaging – sklearn.metrics.f1_score(average=’macro’),
- Hamming-Loss – sklearn.metrics.hamming_loss
- Jaccard similarity coefficient – sklearn.metrics.jaccard_similarity_score
- AUC – sklearn.metrics.roc_auc_score
- Exact Match Ratio – sklearn.metrics.accuracy_score
Multi-label classification in business
Usage of multi-label classification is becoming more and more popular on the market. A lot of companies and institutions are implementing ML classification as a part of their digitalization strategies which helps them to gain competitive advantage.
")
