Der Aufstieg multimodaler Modelle: Über Einzelsinn-AI-Lösungen hinaus

Agata Chudzińska
AI Manager
08. November 2023
Im komplexen Feld der künstlichen Intelligenz hebt sich die Entstehung multimodaler Modelle als eine bedeutende Entwicklung hervor. Während sich KI immer weiter der menschenähnlichen Kognition nähert, ist das Verständnis der facettenreichen Natur dieser Modelle sowohl für Enthusiasten als auch für Unternehmen von entscheidender Bedeutung.
Was ist ein Multimodales KI-System?
Jeder Mensch nimmt die Welt mit mehreren Sinnen wahr. Von den Bildern, die wir sehen, über die Geräusche, die wir hören, bis hin zu den Texturen, die wir fühlen – jeder Sinn trägt dazu bei, uns ein vollständiges Bild unserer Umgebung zu vermitteln. Multimodale KI versucht, diese umfassende sinnliche Erfahrung nachzuahmen. Sie tut dies, indem sie gleichzeitig verschiedene Datentypen verarbeitet, sei es textueller Inhalt, visuelle Bilder oder Audio-Eingaben.
Das Ergebnis? Ein reicheres und detaillierteres Verständnis von Informationen, ganz so, wie wir Menschen die Welt wahrnehmen.
Das KI-Gebiet ist nicht unbekannt, mit KI-Modellen, die Bilder oder Texte verarbeiten können. Frühere Modelle konnten ein Bild analysieren und eine passende Bildunterschrift generieren. Moderne multimodale Modelle, wie GPT-4V (oder das kürzlich angekündigte GPT-4 Turbo) und andere, haben jedoch die Messlatte höher gelegt.
Sie sind für bidirektionale Aufgaben konzipiert, wie z.B. das Umwandeln von textuellen Beschreibungen in visuelle Bilder und umgekehrt, was einen dynamischeren Ansatz zur Dateninterpretation zeigt. Eine wirklich faszinierende Fähigkeit der neuen multimodalen Modelle ist die Möglichkeit, Texte und Bilder zu verflechten – was es ermöglicht, Bilder und Texte sehr flexibel in Ihren Aufforderungen während des Gesprächs zu kombinieren. Ein Beispiel dafür ist im folgenden Bild zu sehen:
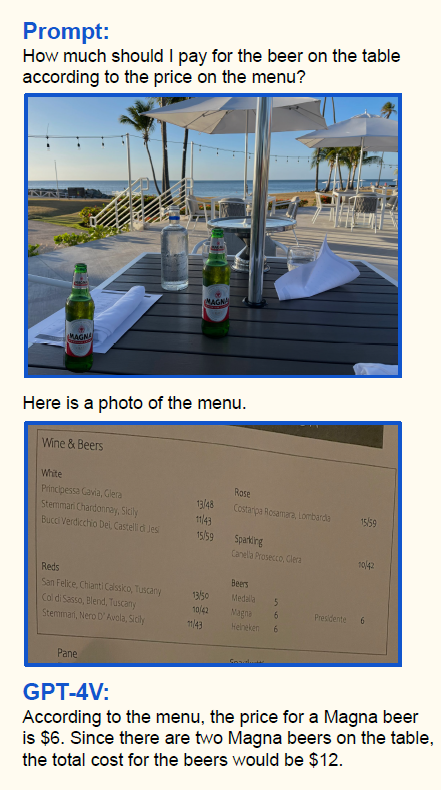
Im dargestellten Beispiel können wir nicht nur sehen, dass das Modell den Namen und die Menge der Biere auf dem ersten Bild richtig erkannt hat, sondern es hat in der gleichen Anfrage den Inhalt der Speisekarte auf dem zweiten Bild analysiert und Informationen aus beiden Bildern kombiniert, um die Frage zu beantworten, was wirklich beeindruckend ist.
Reale Anwendungen von Multimodalen Modellen
Multimodale Modelle haben potenzielle Anwendungen in zahlreichen Sektoren. Beispielsweise:
- E-Commerce: Zusammenführen von textuellen Bewertungen mit Produktbildern für ein reicheres Produktverständnis.
- Gesundheitswesen: Integration von medizinischen Bildern mit Patientennotizen für umfassende Diagnosen.
- Entertainment: Anpassung von Inhalten auf der Grundlage von textlichen und visuellen Benutzerpräferenzen.
Wie Sie sehen, können die Anwendungsfälle für multimodale Anwendungen sehr breit gefächert sein, und mit der kürzlich erfolgten Veröffentlichung von OpenAI’s GPT-4 Turbo mit der Vision API können wir viele neue Szenarien erwarten, die uns bei täglichen Aufgaben sowie bei der Automatisierung von Geschäftsaktivitäten unterstützen werden.
Die zukünftige Landschaft der Multimodalen KI
Die Entwicklung der KI deutet auf immer integriertere, multisensorische Modelle hin. Während die Forschung voranschreitet, erwartet die KI-Gemeinschaft Lösungen, die menschenähnliche Datenverarbeitung nicht nur nachahmen, sondern auch verbessern. Es gibt bereits erste Ansätze zur Kombination weiterer Modalitäten, wie Videos, Audio und sogar 3D-Daten für einen ganzheitlicheren Ansatz.
Während GPT-4V Aufmerksamkeit erregt hat, ist es nur eines von vielen in dem sich ausweitenden Universum der multimodalen Modelle. Ähnlich wie bei den Large Language Models (LLM) nähert sich das Gebiet der Large Multimodal Models (LMM) schnell mit Open-Source-Alternativen, wobei Modelle wie LLaVa auch den Fokus auf multimodale Fähigkeiten legen. Da die KI sich weiterentwickelt, ist es wichtig, über verschiedene Modelle und ihre einzigartigen Fähigkeiten informiert zu bleiben.
Fazit
Multimodale KI-Modelle sind der nächste große Schritt in der Welt der künstlichen Intelligenz. Sie bieten uns einen umfassenderen Blick auf die Datenverarbeitung und könnten die Art und Weise, wie wir mit Technologie umgehen, grundlegend verändern.
Wenn Sie neugierig auf diese innovativen KI-Lösungen sind und darüber nachdenken, sie zu nutzen, stehen wir Ihnen gerne zur Seite. Unser erfahrenes Team hilft Ihnen, die spannenden Möglichkeiten der multimodalen KI zu entdecken und optimal zu nutzen.
Quellen:
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, Lijuan Wang, The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision), 2023, https://arxiv.org/abs/2309.17421
OpenAI, GPT-4V(ision) System Card, 2023, https://cdn.openai.com/papers/GPTV_System_Card.pdf
LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
Wer wir sind
Bei theBlue.ai sind wir darauf spezialisiert, intelligente KI-Lösungen zu entwickeln, die auf die spezifischen Bedürfnisse und Anforderungen von Unternehmen zugeschnitten sind. Mit unserer Expertise in KI können wir maßgeschneiderte Lösungen erstellen, die darauf ausgelegt sind, die Produktivität zu steigern und die Effizienz in verschiedenen Geschäftsbereichen zu verbessern. Kontaktieren Sie uns, um Ihr eigenes Projekt zu starten.
")