Jak działają algorytmy machine learning?
Na przykładzie LIME i wyjaśnialności modeli

Krzysztof Udycz
Inżynier AI
17 kwietnia 2019
Machine learning i sztuczna inteligencja wkroczyły już do wielu obszarów życia.
Używają ich asystenci głosowi w smartfonach, sugerują nam produkty podczas wirtualnych zakupów czy filmy do obejrzenia dopasowane do naszych gustów.
O ile mogą wydawać się zazwyczaj dobrze dopasowane, jest to dwustronna transakcja. Wybierając sugerowane przez algorytmy rozwiązania, godzimy się na swego rodzaju zaufanie względem tych wyborów.
Zwróćmy uwagę na fakt, że modele, takie jak lasy losowe czy głębokie sieci neuronowe to klasyfikatory (algorytmy określenia klasy decyzyjnej obiektów) uwzględniają tysiące parametrów. Są tak ogromne, że łatwo stracić kontrolę nad rezultatem ich uczenia i powodami wygenerowanych predykcji.
Czarna skrzynka AI, czyli jak działają algorytmy machine learning
Aby łatwo zwizualizować sobie działanie algorytmów machine learning, wystarczy wyobrazić sobie czarną skrzynkę. Algorytmy wykonują operacje dla danych wejściowych by po czasie zwrócić określony wynik. Nie są jednak w stanie w tak naprawdę wyjaśnić człowiekowi jak została podjęta określona decyzja. Przedstawiają układ, o którego działaniu nie posiadamy pełnej wiedzy, dokładnie tak, jakby był zamknięty w czarnej skrzynce.
Dlatego też próba zrozumienia na jakiej podstawie generuje się te prognozy to jeden z kluczowych elementów w pracy nad rozwijaniem rozwiązań sztucznej inteligencji.
Użytkownicy muszą mieć pewność, że model będzie dobrze działał na rzeczywistych danych, zgodnie z wartościowymi metrykami. Jeśli nie będzie on budzić on zaufania, to nie powinien być stosowany.
Interpretowalność modeli i systemów uczenia maszynowego
Z pomocą przychodzi technika zajmująca się wyjaśnialnością złożonych modeli (explainable artificial intelligence), którą często poleca się w sytuacjach kiedy decyzje podejmowane przez AI dotyczą bezpośrednio człowieka.
Ma ona na celu stworzenie klasyfikatorów, które:
- Dostarczają możliwe do zweryfikowania wyjaśnienia, gdzie i w jaki sposób systemy sztucznej inteligencji podejmują decyzje.
- Zachowują wysoki poziom wydajności uczenia się wraz z możliwością wyjaśnienia wygenerowanych danych. Obecnie modele o wysokim poziomie dokładności przewidywania są słabo interpretowalne.
- Wynik jak i przewidywania są generowane równocześnie.
Dlaczego wytłumaczalna sztuczna inteligencja jest tak ważna?
Tak jak wspominałem, istnieje szereg powodów, dla których “wytłumaczalność” sztucznej inteligencji jest tak ważna. Zaliczają się do nich między innymi:
- Budowanie zaufania – Czy możemy ufać, że nasze przewidywania są poprawne? Czy modele, których nie rozumiemy mogą krzywdzić ludzi?
- Kontrola – Czy wiemy dokładnie jak zachowuje się nasz system AI?
- Poczucie bezpieczeństwa – Czy na podstawie wyjaśnień każda decyzja może zostać poddana przepisom bezpieczeństwa i ostrzeżeniom o ich naruszeniu?
- Ocena predykcji – Czy możemy rozumieć zachowanie modelu? Czy wyjaśnienia są wystarczające? Czy nasze dane zachowują się tak jak się spodziewaliśmy?
- Ulepszenie i poprawa modelu – Jak możemy ulepszyć, ocenić i ewentualnie poprawić nasz klasyfikator na podstawie wyjaśnień?
- Lepsze podejmowanie decyzji – Czy nasz model jest inteligentny? Czy dzięki wyjaśnieniom możemy podejmować lepsze decyzje?
Z technicznego punktu widzenia, wyjaśnialność systemów uczenia maszynowego okazuje się kluczowa, ponieważ daje poczucie kontroli i bezpieczeństwa oraz pozwala stwierdzić czy nasz model zachowuje się w poprawny sposób.
Ponadto, buduje zaufanie z klientami, którzy mogą przejrzeć uzasadnienia podjętych decyzji czy pozwala na lepsze przestrzeganie aktów prawnych (takich jak RODO / GDPR), w których przysługuje prawo do wyjaśnień.

Only 1 mistake!

Wyniki klasyfikatora rozpoznającego czy na zdjęciu znajduje się wilk czy pies rasy husky. Źródło: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
Spójrzmy na przedstawiony powyżej przykład. Przedstawia on wynik klasyfikatora rozpoznającego czy na zdjęciu znajduje się wilk czy pies rasy husky. Widać, że jest to system o wysokiej precyzji przewidywania – pomylił się on tylko jeden raz. Model stwierdził, że na zdjęciu w lewym dolnym rogu znajduje się wilk, chociaż w rzeczywistości jest to pies rasy husky. Pozostałe obrazy zostały sklasyfikowane poprawnie.
Nasuwa się więc pytanie: “które podejście jest lepsze?”. Ślepo wierzące w poprawność modelu i bazujące jedynie na mierze oceny jakości przewidywań, czy próbujące wyjaśnić na jakiej podstawie zostały podjęte decyzje?

Wyniki klasyfikatora rozpoznającego czy na zdjęciu znajduje się wilk czy pies rasy husky oraz informacje na podstawie której części obrazu model podjął decyzję. Źródło: Explaining Black-Box Machine Learning Predictions – Sameer Singh.
Na powyższej ilustracji widzimy, które części obrazu były informatywne dla naszego klasyfikatora. Okazuje się, że zamiast wilków, wykrywa on śnieg! Gdyby nie podejście do wyjaśnialności modeli sztucznej inteligencji nie wiedzielibyśmy, że decyzje podejmowane są na podstawie niewłaściwych części zdjęcia.
Tak więc odpowiedź brzmi: nie należy ślepo ufać modelowi! Nie wiedząc na jakiej podstawie dokonuje on wyborów, nie wiemy czy to odpowiedni sygnał, hałas czy tło. Kluczowa okazuje się tu zatem próba zrozumienia jego działania i wygenerowania wyjaśnień.
LIME - Local Interpretable Model-Agnostic Explanations
Z pomocą przychodzi framework LIME, którego głównym zadaniem jest wygenerowanie wyjaśnień przewidywania dowolnego klasyfikatora lub regresora uczenia maszynowego.
Narzędzie to zostało napisane w językach programowania Python oraz R. Jego główną zaletą jest możliwość wyjaśnienia i interpretacji wyników modeli wykorzystujących dane tekstowe, tabularyczne czy obrazy.
Klasyfikator i regresor - czy znasz te pojęcia?
Klasyfikator przewiduje ze zdefiniowanego zbioru klasę lub kategorię dla danej obserwacji, np. wiadomość e-mail może zostać oznaczona jedną z dwóch klas: “spam” lub “ham” (wiadomość, która nie jest spamem).
Natomiast regresor stara się oszacować wartość rzeczywistą – liczbę całkowitą lub zmiennoprzecinkową. Liczba ta nie jest wcześniej zdefiniowana w jakimkolwiek zbiorze, np. przewidując za jaką kwotę zostanie sprzedany dom możemy dostać kwotę np. z przedziału PLN 400,000 do PLN 700,000.
Rozwinięcie akronimu “LIME” wskazuje na jego kluczowe cechy, czyli:
- Local – używa lokalnie ważonej regresji liniowej,
- Interpretable Explanations – pozwala na zrozumienie co model robi, które cechy wybiera w celu stworzenia klasyfikatora,
- Model-Agnostic – traktuje model jako czarną skrzynkę.
Jak działa LIME?
Wyjaśnienie generowane jest poprzez przybliżenie modelu oryginalnego (czarnej skrzynki) do modelu wyjaśnianego (takiego jak klasyfikator liniowy z kilkoma niezerowymi parametrami). Interpretowalny model stworzony jest na podstawie perturbacji oryginalnej instancji, z której zostały wyłączone wybrane komponenty. Może to być przykładowo usunięcie słów lub ukrycie części obrazu.
Wyobraźmy sobie, że chcemy wyjaśnić klasyfikator, który przewiduje jak prawdopodobne jest, że na danym obrazie znajduje się żaba drzewna. Pierwszym krokiem jest podział zdjęcia na możliwe do interpretacji części.

Przekształcanie obrazu przedstawiającego żabę drzewną w komponenty możliwe do interpretacji. Źródło: Marco Tulio Ribeiro.
Następnie modyfikujemy obraz na wiele sposobów włączając lub wyłączając niektóre z interpretowalnych komponentów (w przypadku obrazu wyłączone obszary są zaszarzone). Dla każdego z wygenerowanych zdjęć otrzymywane jest prawdopodobieństwo z jakim znajduje się na nim żaba drzewna (zgodnie z naszym modelem).
Kolejny krok stanowi tutaj nauka liniowego modelu ważonego lokalnie na otrzymanym zbiorze danych, dzięki czemu możemy zrozumieć jak zachowuje się on w niewielkim lokalnym otoczeniu. Jako końcowy wynik działania algorytmu (wyjaśnienie oryginalnego modelu) przedstawiane są komponenty o najwyższych wagach.
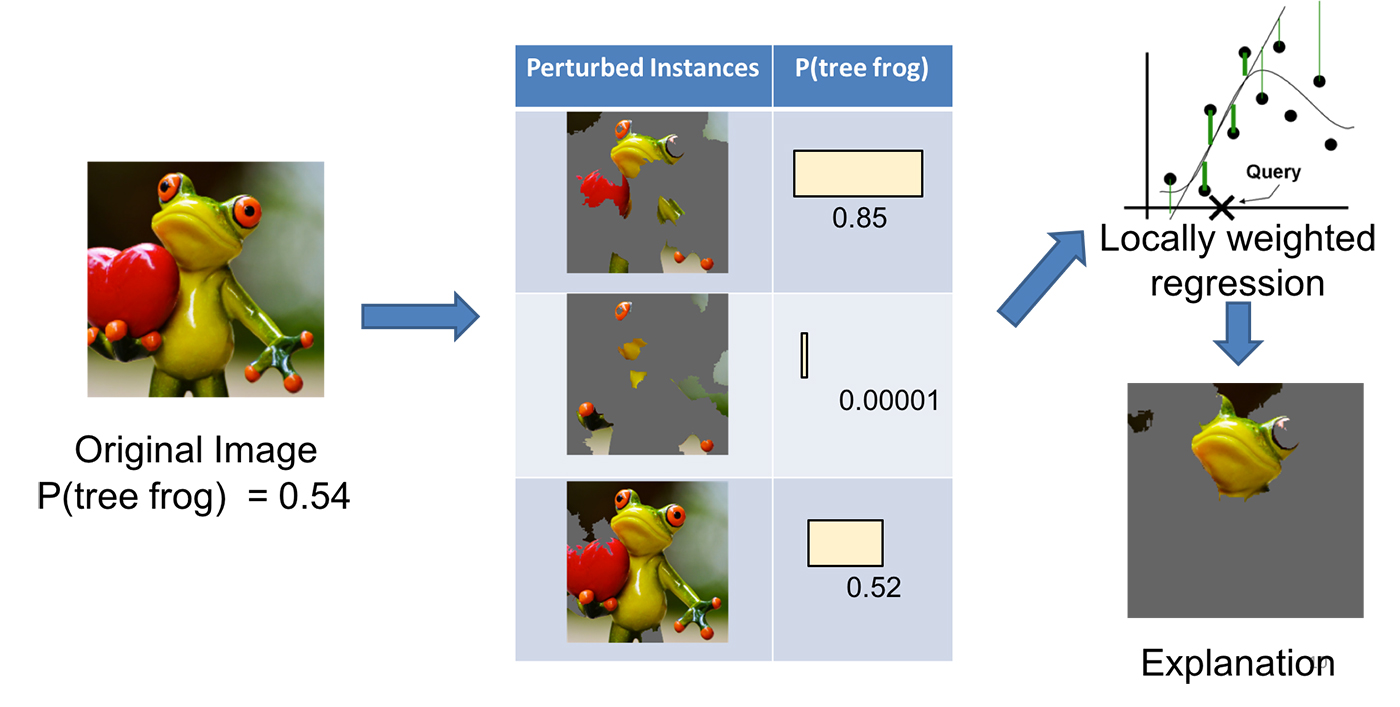
Schemat generowania wyjaśnień modelu za pomocą frameworku LIME. Źródło: Marco Tulio Ribeiro.
LIME - przypadek użycia
20 Newsgroup dataset to zbiór około 20 000 dokumentów podzielonych na 20 tematów z grup dyskusyjnych (m.in. sport, chrześcijaństwo, ateizm czy elektronika). Jest to jeden z najpopularniejszych zbiorów danych używanych w przetwarzaniu języka naturalnego (NLP).
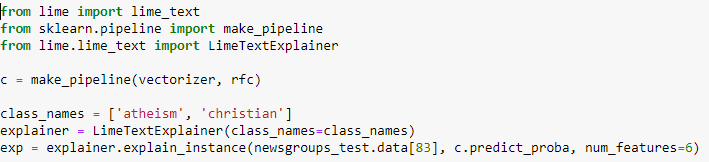
Załóżmy, że stworzyliśmy klasyfikator lasów losowych, który rozróżnia do której z dwóch grup tematycznych (chrześcijaństwo czy ateizm) należy dany tekst. Poniżej przedstawiony jest kod, za pomocą którego można wygenerować wyjaśnienia dla tekstu.
Przykładowy tekst znajdujący się w 20 Newsgroup dataset dla którego zostaną wygenerowane wyjaśnienia. Źródło: Marco Tulio Ribeiro.
Kod przedstawiający generowanie wyjaśnień za pomocą narzędzia LIME. Źródło: Marco Tulio Ribeiro.
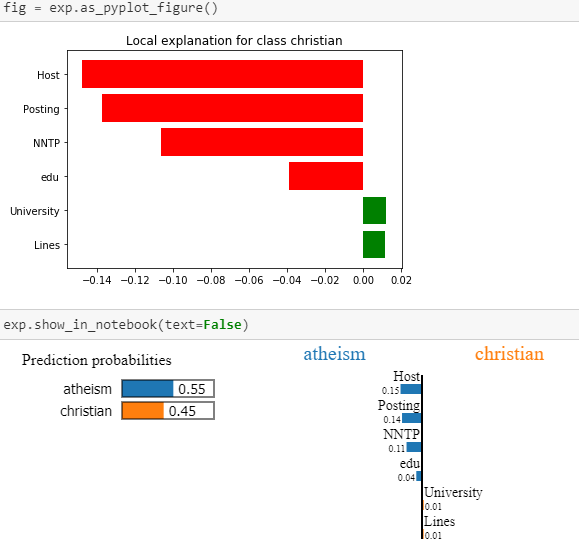
Wyjaśnienia wygenerowane za pomocą narzędzia LIME. Źródło: Marco Tulio Ribeiro.
Widać zatem, że w przypadku powyższego tekstu, model przewiduje przynależność do klasy “ateizm” głównie na podstawie słów: ‘Host’, ‘Posting’, ‘NNTP’ czy ‘edu’.
Jednak LIME to nie jedyny framework, którego możemy użyć do interpretowalności modeli. Zaliczają się też do nich przykładowo:
- DALEX https://github.com/pbiecek/DALEX
- SHAP https://github.com/slundberg/shap
- ELI5 https://eli5.readthedocs.io/en/latest/
- RandomForestExplainer (R package)
- XgboostExplainer (R package)
Przykładowe zastosowanie interpretowalności modeli i systemów sztucznej inteligencji w biznesie i nauce
Interpretowalność modeli sprawdza się w wielu obszarach działalności biznesowej i naukowej, takich jak:
- Wykrywanie zachowań odbiegających od normy – identyfikacja i wytłumaczenie wydarzeń oraz nietypowych zachowań,
- Wykrywanie oszustw – identyfikacja i wyjaśnienie, dlaczego niektóre transakcje traktowane są jako oszustwa,
- Opiniowanie kredytów i pożyczek – identyfikacja i wytłumaczenie, dlaczego dany klient będzie w stanie spłacić wierzytelność, a inny nie,
- Kampanie marketingowe, targetowanie reklam – zwiększenie trafności ofert i wiadomości oraz dopasowanie treści do realnych i najważniejszych interesów kupców,
- Diagnostyka medyczna,
- Automatyzacja pojazdów,
- I wiele innych.
Modele machine learning i sztucznej inteligencji znajdują zastosowanie w wielu dziedzinach naszego życia m.in. w medycynie, prawie, transporcie finansach czy ochronie. Biorąc pod uwagę, że bardzo często mają one bezpośredni wpływ na człowieka, niezwykle ważne jest zrozumienie na jakiej podstawie podejmują one decyzje. Z pomocą przychodzi technika zajmująca się wyjaśnialnością złożonych modeli AI.
Chcesz skorzystać z możliwości sztucznej inteligencji w swojej firmie?