Federated Learning

Marcin Borzymowski
Inżynier AI
2 września 2019
Przetwarzanie danych zgodnie z przepisami o ochronie danych osobowych
Aby wyszkolić dobre modele sztucznej inteligencji (AI), potrzeba dużo danych, a dostęp do nich przeważnie stanowi problem. Wiele projektów wymaga personalnych danych, których nie możemy otrzymać od organizacji. Genialne pomysły, które dają nam ogromną wartość dodaną, takie jak automatyczne wykrywanie patologii w sektorze opieki zdrowotnej, bardzo często nie mogą zostać zrealizowane, ponieważ niezbędnych w tym celu danych nie możemy wykorzystać ze względu na ich ochronę. Istnieje wiele przykładów, w których ochrona danych jest bardzo istotna, jednak byłoby wspaniale, gdyby istniała możliwość ich wykorzystania, zwłaszcza w projektach, które wnoszą wartość dodaną dla społeczeństwa.
Tu pojawia się Federated Learning (FL), który stanie się nowym modelem biznesowym AI. Rozwiązuje problemy z dostępem do danych w inteligentny sposób, nie naruszając przy tym przepisów o ochronie danych osobowych (co jest ważne w UE ze względu na RODO). Dzięki FL budujemy dokładniejszą sztuczną inteligencję bez dostępu do danych, przenosząc obliczenia do urządzeń końcowych. Możliwości AI są wykorzystywane tam, gdzie występują dane i agregowane są tylko wyniki z różnych urządzeń końcowych, tworząc znacznie elastyczniejszą i dokładniejszą sztuczną inteligencję. Dane użytkowników urządzenia końcowego nie są przesyłane. Zapewnia to bezpieczeństwo użytkowników, chroni ich dane i nadal umożliwia szkolenie AI. Przenoszenie obliczeń na urządzenia użytkowników końcowych pozwala również zaoszczędzić pieniądze – nie potrzebujesz już potężnego serwera do szkolenia modeli!
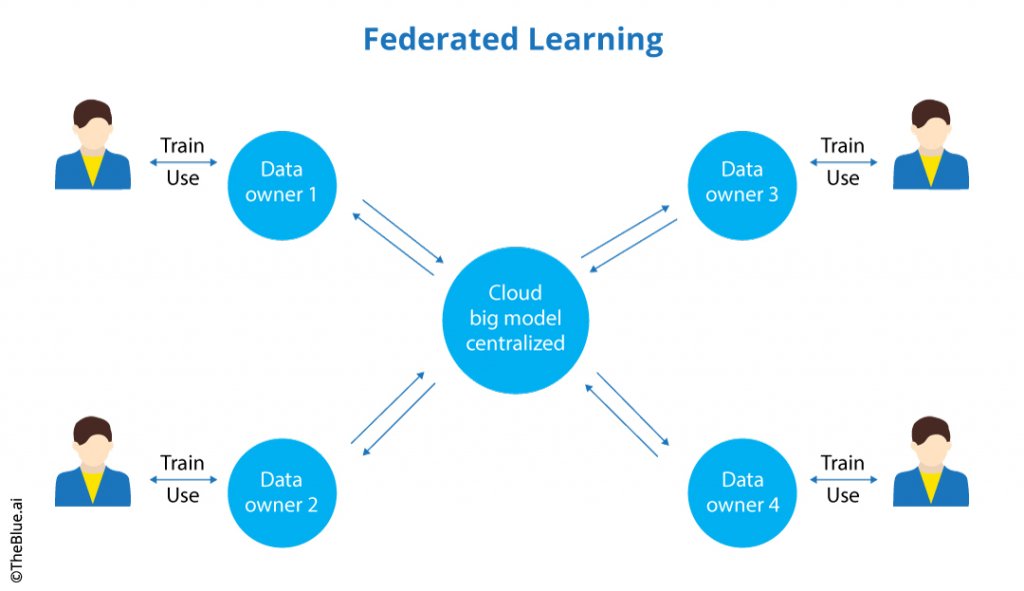
Czym jest Federated Learning?
Federated Learning to oparta na współpracy metoda uczenia maszynowego ze zdecentralizowanymi danymi i wieloma urządzeniami klienckimi. Podczas procesu FL każdy klient (fizyczne urządzenie, na którym przechowywane są dane) trenuje model na swoim zbiorze danych, a następnie wysyła go na serwer, gdzie model jest agregowany do jednego modelu globalnego, a następnie ponownie dystrybuowany do klientów.
FL jest nie tylko procesem szkoleniowym, ale także definiuje całą infrastrukturę do przygotowania takiego procesu na urządzeniach klienckich i agregacji aktualizacji modelu AI w celu osiągnięcia większej dokładności.
Głównym celem FL jest nieingerowanie w dane klienta. W dzisiejszych czasach informacje, które wytwarza przeciętny użytkownik, są bardzo wrażliwe i jak widzimy – bardzo cenne. Ludzie najczęściej nie chcą udostępniać danych, takich jak słowa, które wpisują na klawiaturze mobilnej lub dane medyczne związane z określonym pacjentem.
FL jest bardzo ważny w przypadku urządzeń mobilnych. W klasycznym szkoleniu modelowym musimy wysyłać dane klienta na serwer (bardzo często naprawdę duże zbiory danych). W przypadku Federated Learning wysyłamy tylko niewielką porcję danych liczbowych modeli AI.
Plusy i minusy – porównanie ze standardowym treningiem
Zalety
- Obliczenia przeniesiono na urządzenia użytkowników końcowych
- Większa dokładność modelu dzięki dostępowi do różnych danych
- Bezpieczniejsze aplikacje – nie przesyłamy danych użytkownika na serwer
- Możemy niskim kosztem przeszkolić wiele modeli jednocześnie
Wady
- FL warto stosować tylko wtedy, gdy urządzenie użytkownika końcowego posiada różne dane, które nie powinny być wynoszone z urządzenia
- Musimy budować proste i bardzo skuteczne architektury AI (szczególnie dla urządzeń mobilnych)
- Obecnie (sierpień 2019 r.) nie mamy platformy Federated Learning dla programistów, więc aby w pełni zapewnić proces FL, musisz zbudować własną platformę lub poczekać, aż jedna z dużych firm, takich jak Google lub Amazon, utworzy taką platformę
- Weryfikacja modelu AI może być trudna z powodu „treningu bez danych”
Kolejną dużą zaletą FL, o której warto wspomnieć, jest zawsze zaktualizowany model nigdy nie widzianych danych. Załóżmy, że kupiłeś produkt AI Federated Learning, który ma inna firma. Twój zestaw danych zaktualizuje model globalny (który otrzymasz w aktualizacji), podobnie jak zestawy innych firm. Możemy to porównać do ludzi dzielących się swoją wiedzą z innymi. Udostępnianie modelu bez udostępniania danych to korzyść dla wszystkich organizacji.

Przykłady użycia
Pod warunkiem, że przetestowaliśmy koncepcję FL, możemy jej używać w każdym szkoleniu AI. To bardzo dobra informacja, ponieważ FL daje nam wiele korzyści bez ograniczeń.
Używanie FL w każdej sytuacji nie jest konieczne. Załóżmy, że budujemy system rekomendacji dla naszego sklepu internetowego. Jego zadaniem jest oferowanie określonym użytkownikom nowych produktów na podstawie jego historii wyświetleń. W tym przypadku mamy odwiedzających (klientów) i sklep internetowy (serwer). Dlaczego więc nie możemy korzystać z Federated Learning? Istnieje jedna prosta odpowiedź na to pytanie – jest to nadmiar formy. Każdy odwiedzający generuje dane, które możemy po prostu od niego pobrać, obsługując go. Oznacza to, że gdy klient odwiedza daną stronę produktową, nasz serwer musi wykonać skrypty i wysłać tę stronę (z informacjami o produkcie – naszymi danymi dla AI) do klienta. Serwer może anonimizować te dane za pomocą identyfikatora użytkownika, a następnie zapoznać się ze schematem wyboru produktów przez klientów.
Powinniśmy skorzystać z Federated Learning, gdy mamy aplikację, którą można zainstalować na urządzeniu użytkownika i przetwarza ona poufne dane. Powinniśmy również rozważyć, czy klasyczne metody uczenia się są wystarczające do naszych zadań. Wdrożenie infrastruktury FL kosztuje więcej niż korzystanie z klasycznie wyszkolonych modeli. Dobrym przykładem jest GBoard (klawiatura Google dla urządzeń z systemem Android). Wykorzystuje proces FL, aby dowiedzieć się, jak pewna grupa ludzi używa słów podczas budowania zdań i dodaje nowe słowa do słownika innego klienta.
Przykład użycia: zadanie NLP
- Generowanie nagłówków
- Streszczenia rozmów – dane osobowe
- Przewidywanie następnego słowa
- Sprawdzanie błędów w pisowni
Przykład użycia: przetwarzanie obrazu
- Zliczanie odwiedzających
- Konwertowanie rozpoznanego pisma ręcznego
- Wykrywanie obiektów
- Wykrywanie anomalii
W każdym przypadku używa się wielu źródeł danych, aby zbudować lepszą sztuczną inteligencję dystrybuowaną dla każdego źródła.
Zastosowanie w opiece zdrowotnej
Opieka zdrowotna jest jednym z najlepszych przykładów zastosowania Federated Learning. Mamy tu do czynienia z mnóstwem danych osobowych, których szpitale, prywatni lekarze, zakłady ubezpieczeń, instytuty badawcze itp. nie mogą udostępnić. Dane dotyczą chorób, ich postępu, leczenia, leków i konsekwencji ich stosowania, genetyki i wielu innych czynników wpływających, a także oświadczeń, które miałyby wielką wartość dla medycyny. Dane te są jednak danymi osobowymi i podlegają rozporządzeniu o ochronie danych (RODO). Jak więc wytrenować model bez tych danych? Tu wkracza Federated Learning. Wyniki szkolenia są wysyłane na serwer, na którym przechowywane są również rezultaty innych lekarzy prowadzących badania na ten sam temat. Na tym serwerze tworzony jest globalny model AI o większej dokładności uzyskanej dzięki wynikom szkolenia przekazywanym z powrotem do urządzeń końcowych. Nie ma wymiany danych osobowych, a jednocześnie lekarze zawsze pracują z aktualnymi i coraz bardziej precyzyjnymi algorytmami, które szkolą w społeczności niezależnie od lokalizacji. Analizując obrazy AI może wspierać ludzi podczas diagnozowania, np. wykrywania nowotworów lub uszkodzenia kości.

Przykład rozpoznawania głosu
Żyjemy w epoce cyfrowych asystentów. Coraz więcej osób korzysta z nich w życiu codziennym, aby nadążać za zmianami. Posiadanie w domu urządzenia wspomaganego przez asystenta jest kontrowersyjne ze względu na kwestię prywatności. Aby skorzystać z asystenta, musisz wypowiedzieć słowo aktywujące, a następnie wydać polecenie. Takie urządzenia nie powinny nagrywać naszego głosu przez cały czas i czekać na komendę, więc możemy użyć Federated Learning do szkolenia modelu w celu lepszego rozpoznawania słowa aktywującego i zapobiegania słuchania nas 24/h, utrzymując nasze sekrety w tajemnicy.
Frameworki
Jak wspomniałem wcześniej, dobrym przykładem użycia FL jest GBoard, więc Google daje nam framework dla Federated Learning – Tensorflow Federated (TFF). Na razie otrzymaliśmy tylko środowisko symulacyjne do uczenia modeli na zdecentralizowanych danych bez protokołów sieciowych – wersję beta. TFF ma dobrą dokumentację, a co najważniejsze – jest to wersja open source. Wiele osób oczekuje innego (lepszego) algorytmu agregacji modeli, więc pozostaje nam czekać na aktualizacje.
Mamy też OpenMinded. Zbudowano część platformy FL i przetestowano kod na dwóch Raspberry Pi, ale…
“Cały proces instalacji odpowiedniej wersji Pythona, Pytorch, PySyft, wraz ze wszystkimi wymaganymi zależnościami zajął mi kilka dni.“ ~FL samouczek na ich blogu.
Jest też inny projekt – FATE. Wykonali prawie taką samą pracę jak OpenMinded i czekają na pracę współtwórców na GitHub.
Można powiedzieć, że każdy rodzaj frameworku Deep Learning może obsłużyć symulację Federated Learning. Chodzi tutaj o wdrożenie dobrego algorytmu agregacji.
Nasze wyniki
Segmentacja obrazu
Użyliśmy Fast.AI & PyTorch w celu segmentacji obrazu FL w wielu scenariuszach. Jak widzimy Federated Learning może nam zapewnić większą dokładność dla tej samej liczby epok. Podzieliliśmy zbiór danych CAMVID na ośmiu klientów, a następnie przygotowaliśmy dwa scenariusze. W pierwszym, co jedną epokę u każdego klienta po prostu uśrednialiśmy wagi modelu (łącznie 48 epok) i wysyłaliśmy je do klientów. W drugim scenariuszu co 3 epoki agregowaliśmy model dla każdego klienta i dystrybuowaliśmy go 16 razy (łącznie 3 × 16 epoki).
Scenariusz
Ostateczny wynik
1 epoka na każdym kliencie i 48 agregacji
(agregacja co każdą epokę)
~86.98%
3 epoki na każdym kliencie i 16 agregacji
(agregacja co 3 epoki)
~87.12%
Uśrednianie wag modeli powodowało niestabilność uczenia się, ale dawało większą dokładność.
Przegląd analizy sentymentu
Tutaj użyliśmy TensorFlow Federated & Keras z zestawem danych IMDB. Wyniki były prawie takie same jak w przypadku eksperymentu z segmentacją obrazu, ale stwierdziliśmy, że uśrednianie TFF (uśrednianie wagi modelu) dawało wyższą stabilność uczenia się.
Perspektywy
Wierzę, że Google zbuduje platformę FL i dostarczy nam narzędzia do łatwej i dobrej integracji z innymi językami programowania. Federated Learning będzie stawał się coraz bardziej popularny głównie ze względu na bezpieczeństwo danych, większą dokładność i przenoszenie obliczeń na urządzenia klientów.
Źródła:
- https://www.fedai.org/
- https://www.openmined.org/
- https://arxiv.org/pdf/1902.01046.pdf
- https://medium.com/syncedreview/federated-learning-the-future-of-distributed-machine-learning-eec95242d897
- https://www.youtube.com/watch?v=89BGjQYA0uE
- https://github.com/tensorflow/federated
- https://arxiv.org/pdf/1811.03604.pdf
Chcesz korzystać ze sztucznej inteligencji w swojej firmie?