Federated Learning / Föderales Lernen

Marcin Borzymowski
KI Ingenieur
2. September 2019
Datenverarbeitung unter der Einhaltung der Datenschutzbestimmungen
Um gute Künstliche Intelligenz (KI) Modelle zu entwickeln, werden große Datenmengen benötigt. Es gilt das Prinzip: Je mehr Daten zum Trainieren, desto besser und zuverlässiger der Algorithmus. (Je öfter wir etwas machen, desto besser werden wir, ähnlich ist es hier.) Doch an große Datenmengen zu kommen, könnte zur Herausforderung werden, besonders wenn diese Datenschutzbestimmungen (z.B. DSGVO) unterliegen. Der Datenschutz hat seine gute Berechtigung, aber es erschwert den Zugang zu bestimmten Daten, deren Auswertung sehr wertvolle und für uns alle relevante Informationen liefern könnte z.B. im Bereich der Gesundheit und Medizin. Es gibt viele solcher Beispiele. Dies lässt bestimmte Forschungsprojekte stagnieren oder gar nicht erst umsetzten, weil die Daten nicht benutzt werden dürfen, um Missbrauch zu verhindern.
Die Lösung: Föderales Lernen (FL)! Ein KI-Prozess, das das Problem um den Datenzugriff auf eine sehr intelligente Art und Weise löst ohne den Datenschutz zu verletzen (wegen DSGVO in Europa besonders wertvoll). Beim Föderalem Lernen (engl.: Federated Learning) werden die KI-Berechnungen, die für das Training des Algorithmus so wichtig sind, auf dem Endgerät selbst gemacht, also dort, wo die Daten entstehen bzw. eingetragen werden. Lediglich die Resultate der Berechnungen, die Lernergebnisse des Algorithmus werden übertragen und zusammengeführt. Die sensiblen Daten gehen gar nicht erst raus. So kommen die Ergebnisse verschiedener Endgeräte (Rechner, Handy etc.) zusammen und lassen eine äußert präzise Künstliche Intelligenz entstehen. Diese elegante Möglichkeit bietet Datenschutz und ermöglicht dennoch die KI-Schulung. Netter Nebeneffekt: Die Verlagerung der Berechnungen auf die Endgeräte spart bares Geld, da die leistungsstarken Server nicht mehr benötigt werden.
Was ist Federated Learning?
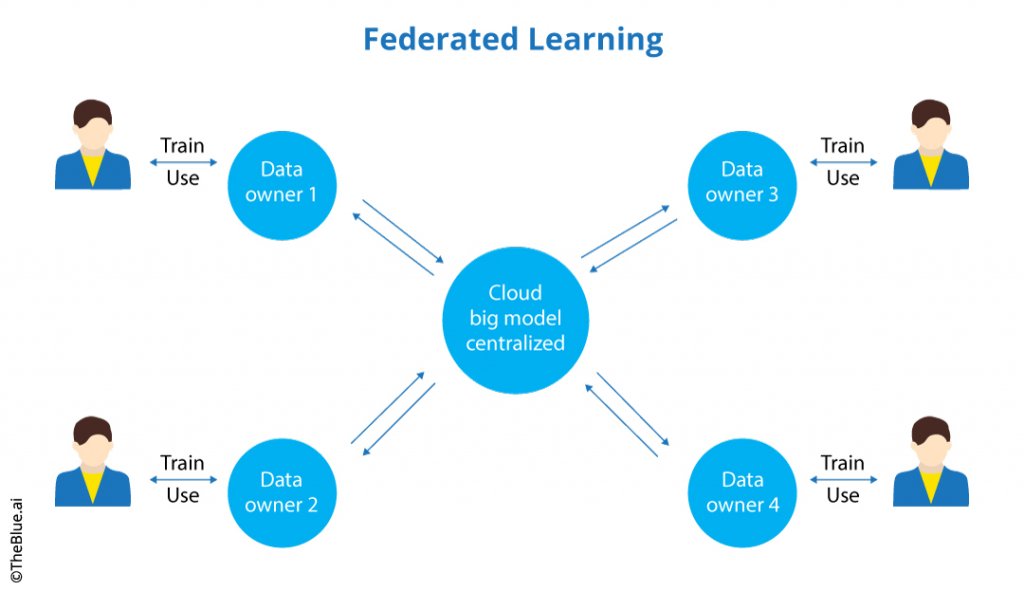
Federated Learning ist eine kollaborative bzw. gemeinschaftliche Methode des maschinellen Lernens mit dezentralen Daten und unterschiedlichen Nutzer-Geräten. Während des FL-Prozesses trainiert jeder Nutzer (mit einem physischen Endgerät, wie Laptop oder Smartphone, auf dem die Daten gespeichert sind) das KI-Modell mit seinem Datensatz und sendet anschließend das Resultat-Modell an den Server, wo alle eintreffenden Modelle zu einem globalen Modell zusammengefasst werden und dann wieder auf die Endgeräte der Nutzer verteilt werden.
FL ist viel mehr als nur ein Trainingsprozess. Es definiert die gesamte Infrastruktur, um einen solchen Prozess auf den Benutzergeräten vorzubereiten und KI-Modell-Updates zu koordinieren für die höchste KI-Genauigkeit.
Das Hauptziel von FL ist es, Kundendaten nicht zu berühren. Heutzutage sind Daten sehr sensibel und sehr wertvoll. Wir wollen keine Daten über über unseren Wörtergebrauch auf dem Handy oder unsere medizinischen Daten, teilen.
FL ist bei mobilen Geräten besonders wichtig. Im klassischen Modelltraining müssen wir Nutzer-Daten an einen Server senden (meist sehr große Datensätze). Mit Federated Learning senden wir nur eine kleine Anzahl von KI-Modellnummern.
Vor- und Nachteile - Vergleich mit klassischem Training
Vorteile
- Berechnungen werden auf Endgeräte gemacht
- Höhere Genauigkeit des KI-Modells durch Training auf unterschiedlichen Daten
- Mehr Sicherheit – Keine Übertragung der Benutzerdaten auf einen Server
- Es können mehrere Modelle gleichzeitig und kostengünstig trainiert werden
Nachteile
- FL ist vorrangig dann sinnvoll, wenn das Endgerät über verschiedene Daten verfügt und keine Daten aus dem Gerät übertragen werden sollen
- Es bedarf einfache und sehr effektive KI-Architekturen (insbesondere für mobile Geräte)
- Zurzeit (August 2019) gibt es keine FL-Plattform für Entwickler. Für ein komplettes FL-Projekt, müsste man sein Eigenes bauen
- KI-Modellverifizierung kann durch das Training “ohne” Daten zur Herausforderung werden
Ein weiterer großer Vorteil von FL, den man nicht außer Acht lassen sollte, es sind immer aktualisierte KI-Modelle durch nie gesehene Daten. Nehmen wir an, Sie haben ein KI FL-Produkt gekauft, das eine andere Firma auch hat. Ihr Datensatz aktualisiert das globale Modell (das Sie in einem Update erhalten), genauso wie der Datensatz anderer Unternehmen. Wir können es mit Menschen vergleichen, die ihr Wissen mit anderen teilen. Dieses Sharing-Modell ohne Datenaustausch ist von gegenseitigem Interesse und Vorteil.

Anwendung
Sofern wir das FL-Konzept geprüft haben, können wir es in allen Fällen des KI-Trainings einsetzen. Das sind sehr gute Informationen, denn FL bringt uns viele Vorteile ohne Abstriche.
Die Verwendung von FL ist nicht immer sinnvoll. Angenommen, wir bauen ein Empfehlungssystem für unseren Online-Shop auf. Seine Aufgabe ist es, bestimmten Besuchern neue Produkte anzubieten, die auf der Grundlage der Verlaufsdaten seiner Produktansichten erstellt wurden. In diesem Fall haben wir nur Besucher (Kunden) und Online-Shop (Server). Warum sollten wir also hier Federated Learning nicht einsetzen? Es gibt eine einfache Antwort auf diese Frage – es wäre ein Übermaß. Jeder Kunde erzeugt Daten, die wir direkt und einfach von ihr/ihm abrufen können, indem wir sie/ihn bedienen. Das bedeutet, wenn ein Kunde eine bestimmte Produktseite besucht, muss unsere Server Skripte ausführen und diese Seite (mit Produktinformationen – Daten für die KI) an den Kunden senden. Ein Server kann diese Daten unter Verwendung der Benutzer-ID anonymisieren und dann das Schema der Produktauswahl durch den Kunden kennenlernen.
Wir sollten Federated Learning verwenden, wenn wir sensible Daten verarbeiten müssen. Wir sollten auch überlegen, ob klassische Lernmethoden für unsere Aufgaben ausreichen. Die Implementierung der FL-Infrastruktur kostet mehr als die Verwendung klassisch trainierter Modelle. Ein gutes Beispiel für FL ist GBoard (Googles Tastatur für Android-Geräte). Es verwendet den FL-Prozess, um zu lernen, wie bestimmte Personengruppen Wörter beim Bilden von Sätzen einsetzten und neue Wörter zum Wortschatz anderer Kunden hinzufügen.
Anwendungsfall: NLP-Aufgabe
- Generierung von Schlagzeilen
- Gesprächszusammenfassungen – persönliche Daten
- Vorhersagen für das nächste Wort
- Überprüfung von Rechtschreibfehlern
Anwendungsfall: Bildverarbeitung
- Zählen von Besuchern
- Umwandlung der handschriftlichen Texterkennung
- Objekterkennung
- Erkennung von Anomalien
In jedem Anwendungsfall werden mehrerer Datenquellen verwendet, um eine bessere KI zu entwickeln, die wiederrum auf jede Quelle verteilt wird.
Beispiel im Gesundheitswesen
Das Gesundheitswesen ist einer der besten Anwendungsfälle für föderales Lernen. Hier haben wir Tonnen von personenbezogenen Daten, die nicht an Krankenhäuser, Privatärzte, Krankenkassen, Forschungseinrichtungen usw. weitergegeben werden dürfen. Die Daten betreffen Symptome, Krankheiten, deren Verlauf, Heilung, Medikamente, Folgen, Genetik und viele andere Einflussfaktoren. Diese Daten enthalten aber auch Aussagen, die für die Medizin von großem Wert wären. Da sie jedoch personenbezogen sind, unterliegen sie den Datenschutzbestimmungen (GDPR). Wie trainiert man also ein Modell ohne diese sensiblen Daten? Hier kommt Federated Learning ins Spiel. Das FL-KI-Modell wird auf den Geräten der jeweiligen Kliniken, Forschungseinrichtung, Praxis etc. installiert und lernt mit den dortigen Daten. Die Trainingsergebnisse werden an einen Server gesendet, wo auch die Ergebnisse anderer Einrichtungen, die zum gleichen Thema forschen, gespeichert werden. Auf diesem Server entsteht auf der Basis aller Trainingsergebnisse ein globales KI-Modell mit höherer Genauigkeit, das wieder an die Endgeräte der Einrichtungen verteilt wird. Es findet kein Datenaustausch von personenbezogenen Daten statt und gleichzeitig arbeiten die Ärzte immer mit aktuellen und immer präziseren Algorithmen, die sie in einer ortsunabhängigen Community ausbilden. Die KI kann den Menschen bei der Diagnose unterstützen, z.B. bei der Erkennung von Tumoren oder Knochenschäden auf Basis von Bildern.

Beispiel für Spracherkennung
Heutzutage herrscht eine Ära der digitalen Assistenten. Immer mehr Menschen nutzen sie auch im Alltag. Geräte, die Assistenten betriebenen werden, sind umstritten wegen der Privatsphäre. Um den Assistenten zu verwenden, müssen Sie das „Wake“-Wort und dann den Befehl sagen. Solche Geräte sollten unsere Stimme nicht ständig aufzeichnen und auf den Befehl warten, so dass wir mit Federated Learning das Modell für eine bessere Erkennung des Wake-Worts trainieren und verhindern können, dass es uns die ganze Zeit zuhört.
Frameworks
Wie ich bereits erwähnt habe, ist GBoard ein gutes Beispiel für einen Anwendungsfall für FL, so dass Google uns einen Rahmen für Federated Learning – Tensorflow Federated (TFF) bietet. Es stellt uns zunächst nur eine Simulationsumgebung für Trainingsmodelle auf dezentralen Daten ohne Netzwerkprotokolle zur Verfügung – Beta-Version. TFF hat eine gute Dokumentation und was am wichtigsten ist – es ist Open-Source. Viele Leute fragen nach einem anderen (besseren) Modell-Aggregationsalgorithmus, also müssen wir nur auf Updates warten.
Wir haben auch OpenMinded. Sie haben einen Teil der FL-Plattform gebaut und ihren Code auf zwei Himbeerpillen getestet, aber…
“The whole process of installing the right Python version, Pytorch, PySyft, along with all the requires dependencies took me a couple of days.“ ~FL tutorial on theirs blog.
Es gibt noch eine andere Möglichkeit – FATE. Sie haben fast den gleichen Job wie OpenMinded gemacht und warten auf Mitwirkende bei GitHub.
Wir können sagen, dass jede Art von Deep Learning Framework mit Federated Learning Simulationen umgehen kann. Hier geht es darum, einen guten Aggregationsalgorithmus zu implementieren.
Unsere Ergebnisse
Bildsegmentierung
Wir haben Fast.AI & PyTorch in der FL-Bildsegmentierung in vielen Szenarien eingesetzt. Wie wir festgestellt haben, verhilft Federated Learning zu einer besseren Genauigkeit innerhalb des gleichen Zeitraums.
Wir haben den CAMVID-Datensatz durch 8 Nutzer aufgeteilt und dann zwei Szenarien vorbereitet. In jeder einzelnen Benutzerperiode haben wir nur die Gewichte der Kundenmodelle gemittelt (insgesamt 48 Epochen) und an die Kunden gesendet, in einer Sekunde alle 3 Epochen auf jeden Kunden haben wir das Modell aggregiert und über den Kunden 16-mal verteilt (insgesamt 3×16 Epochen).
Das
Szenario
Endgültige Präzision
1 Epoche auf dem Kunden und 48 Aggregationen
(Aggregation jeder einzelnen Kunden-Epoche)
~86.98%
3 Epochen auf dem Kunden und 16 Aggregationen
(Aggregation alle 3 Kundenepochen)
~87.12%
Die Mittelung der Modellgewichte verursachte Lerninstabilität, gab aber eine bessere Genauigkeit.
Überprüfung der Stimmungsanalyse
Hier haben wir TensorFlow Federated & Keras mit IMDB-Datensatz verwendet. Die Ergebnisse waren fast die gleichen wie beim Experiment zur Bildsegmentierung, aber wir fanden heraus, dass die TFF-Mittelwertbildung (Averaging Model Weight Updates) eine höhere Lernstabilität bietet.
Ausblick
Ich denke, dass Google eine FL-Plattform aufbauen und uns Tools für eine einfache und gute Integration mit anderen Programmiersprachen zur Verfügung stellen wird. Federated Learning wird immer beliebter werden, vor allem wegen der Datensicherheit, der besseren Genauigkeit und der Übertragung der Berechnungen auf die Nutzer-Geräte.
Quellenangabe
- https://www.fedai.org/
- https://www.openmined.org/
- https://arxiv.org/pdf/1902.01046.pdf
- https://medium.com/syncedreview/federated-learning-the-future-of-distributed-machine-learning-eec95242d897
- https://www.youtube.com/watch?v=89BGjQYA0uE
- https://github.com/tensorflow/federated
- https://arxiv.org/pdf/1811.03604.pdf
Sie wollen KI In Ihrem Unternehmen einsetzten?
")